简介说明
OmniVoice 今夕赞助版 是一套基于 OmniVoice 的 Windows 本地整合版文本转语音方案,重点面向语音克隆、音色设计、字幕配音、多人对话生成、剧本配音以及阅读 App 听书 API 接入等场景。
这次更新的核心,不只是“功能变多了”,而是实际使用体验有了非常明显的提升。
最直观的变化有两个:
以前启动经常要等几分钟,现在多数情况下几十秒就能进入可用状态
以前生成音频往往要等几分钟,现在很多任务十几秒就能出结果
这不是夸张说法。如果你愿意,完全可以把旧版本和当前版本都下载下来,自己实测对比。
OmniVoice 今夕整合版升级改进日志
一、本轮重点升级
1. 启动与模型加载
这一轮首先重点处理了启动速度和本地模型加载逻辑。
已补强本地模型路径解析,优先加载本地模型,不再轻易误退回仓库路径
启动日志中已明确输出模型加载位置、设备信息、端口信息,排查问题更直观
ASR 已接入启动时预加载逻辑,并优先使用本地 Whisper 缓存
这部分改动带来的实际提升非常明显。
之前很多用户最直观的不满,就是“启动慢、等待长、第一次识别要等很久”。现在这一块已经明显改善,整体节奏会顺很多。
2. 页面与工作流优化
除了底层提速,页面上的常用操作也做了重新调整,让工作流更贴近真实使用习惯。
字幕配音、剧本工坊 的生成按钮已移动到输出音频区域上方,更符合常用操作路径
剧本工坊 的句间停顿默认值调整为 0.5
自动绑定同名角色音色 已恢复并默认勾选
角色下拉切换时,已恢复同名音色自动选中能力
这类改动看上去不算“炫技”,但对实际使用影响很大。
尤其是在剧本工坊、多人配音这类需要反复调整角色和音色的场景里,少一点来回点击,整体体验就会顺很多。
3. 音色库管理增强
音色库这次也补强了不少实用能力。
支持搜索、预览、重命名、删除、备注
支持把音色一键回填到主表单、字幕默认音色、剧本默认音色
音色库管理 页面新增“上传音色并保存”区域,不需要再绕回语音工作台操作
这意味着现在的音色库不只是“放音频的地方”,而是更接近一个真正可管理、可复用、可快速调用的音色中心。
4. 字幕配音升级
字幕配音部分,这次主要补齐了更完整的多角色工作流。
支持角色识别配音与普通顺序配音两种模式
支持单角色绑定、多角色批量绑定、批量解绑
支持默认参考音频从音色库一键带入
支持输出处理后的 SRT 字幕
如果你经常做对话类配音、小说字幕配音或者简单的短剧配音,这部分会比以前更省事。
5. 剧本工坊升级
剧本工坊依然是这次升级里的重点区域之一。
支持文本文件输入与直接输入双入口同时常驻显示
支持未标注内容自动归到旁白
支持角色识别、同名音色自动绑定、手动角色绑定、批量角色绑定
长句生成已做分段处理,减少长句异常与发音漂移
角色名解析已补强,可识别带括号后缀的角色名
生成日志中已增加“每个角色实际使用的音频来源”与分段参数记录
这一轮改完之后,剧本工坊更适合真正拿来做多人配音,而不只是做一个简单的文本试玩页面。
6. 中文语言稳定性优化
中文内容这次也专门做了更明确的提示和修正。
主界面、字幕配音、剧本工坊均加入显式中文提示
当前建议:中文内容优先手动选择 Chinese
已避免继续默认误导使用 Chinese (Mandarin)
针对中文误判成粤语的问题,已在 UI 和 API 文档中给出明确提示
这部分虽然看起来只是提示层面的调整,但本质上是在减少误用成本。
尤其是中文用户,之前最常见的问题之一就是语言判断不稳定,现在至少在界面层面已经把这个坑提前标清楚了。
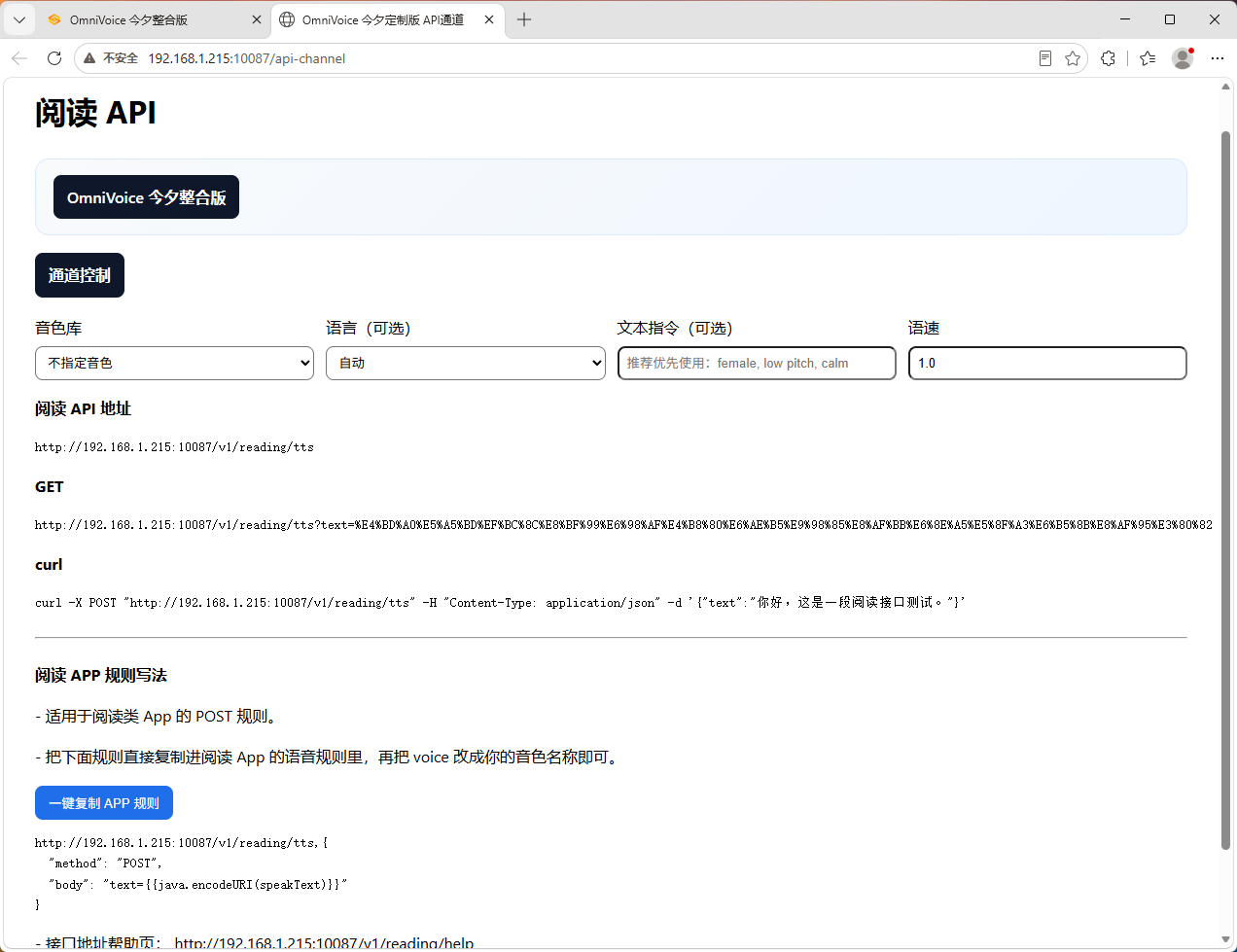
7. 阅读 API 与通道控制
阅读 App 听书接入这次也做了更完整的增强。
阅读 API 文档区新增 speed 参数示例
API 返回头增加本次实际使用的 language 与 speed
API 文档区明确提示:中文请显式传 language=Chinese
已增加在线 APP 规则展示与一键复制能力
“一键复制 APP 规则” 已补强复制兜底逻辑,减少浏览器剪贴板失败
支持阅读 API / 网页合成双通道、API 单通道、合成单通道切换
如果你本身就打算把 OmniVoice 用在阅读 App 听书接入上,这部分改动会明显更实用。
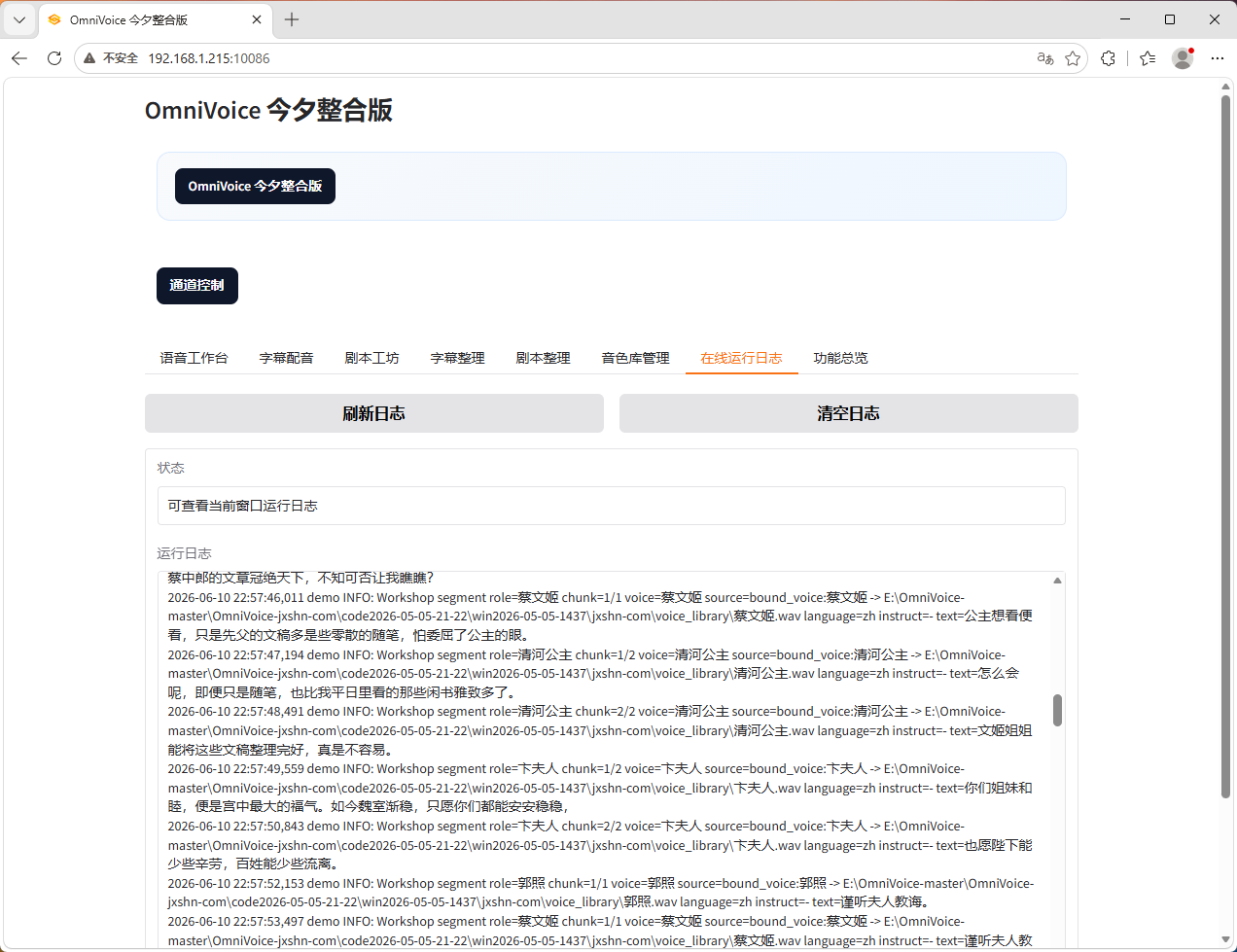
8. 在线运行日志
这次新增了一个独立分页:在线运行日志。
支持刷新日志、清空日志
已补齐主生成、音色库管理、字幕配音、剧本工坊、字幕整理、剧本整理等常用链路日志
日志中增加最终生效参数,后续排查问题更快
这类功能对新手和折腾党都很重要。
因为很多问题并不是“不能修”,而是以前根本看不到关键过程。现在日志补齐之后,定位问题会轻松很多。
二、问题修复与排查结论
1. 本地模型误走仓库路径
已定位根因:本地模型存在,但旧路径解析失败后会静默回退到仓库 ID
现已补强本地路径候选扫描,并在日志中明确显示最终模型来源
2. 剧本工坊异常发音
修复了坏 ref_text 污染导致的异常输出
修复了长句不分段导致的发音漂移
修复了角色名带括号时无法正确映射音色的问题
3. 多音字 / 发音覆盖
已确认当前这版 checkpoint 对该能力支持不稳定
为避免继续误导,当前已将 发音覆盖 / 多音字注音 明确降级为实验功能
当前版本不保证稳定生效.
三、当前建议使用方式
1. 启动方式
优先使用根目录 start_release.bat
2. 中文内容
建议手动选择 Chinese
3. 剧本与字幕
复杂古风文本、多人混合文本、长剧本仍建议人工复核后再批量生成
四、补充说明
当前版本支持 NVIDIA CUDA 加速
非 NVIDIA 环境建议使用对应轻量版本
剧本整理、字幕整理、角色识别、旁白自动归类都属于辅助能力,不保证 100% 准确
五、生成速度测试说明
为了方便大家对实际生成效率有一个更直观的判断,这里补充一组简单测试数据,分别测试了语音克隆模式 和 剧本工坊模式的生成速度表现。
需要先提醒一点:
如果生成内容是中文,建议手动将语言明确设置为 Chinese。
如果使用默认自动识别,模型有时会把普通话误判成粤语,从而影响最终发音效果。
本次测试使用文本为:剧本工坊模式测试文本.txt
总字符数:677 字符
1语音克隆模式(单人朗读)测试
计算结果:677 ÷ 16.79 ≈ 40.32
也就是大约可达到 每秒生成 40 个字符音频 的速度
第二次测试
变量:语速默认 1
生成完成,耗时 16.37 秒
第三次测试
变量:语速调整为 1.5
生成完成,耗时 11.13 秒
第四次测试
变量:语速调整为 0.85
生成完成,耗时 18.55 秒
从这一组结果来看,语音克隆模式下的生成速度整体比较稳定。
在中文内容、单人朗读场景里,默认语速下大约可以维持在十几秒完成 677 字符的水平;语速提高后,整体耗时会进一步缩短,而语速降低时,生成时间会相应变长。
2.剧本工坊模式(多人对话 / 多音色)测试
第一次测试
建议语速:默认 0.5
剧本工坊配音完成,耗时 33.52 秒
第二次测试
建议语速:默认 0.5
剧本工坊配音完成,耗时 38.44 秒
第三次测试
建议语速:默认 0.5
剧本工坊配音完成,耗时 38.60 秒
从结果来看,剧本工坊模式因为涉及 多人角色、多音色切换和更复杂的文本处理流程,整体耗时会明显高于单人语音克隆模式。但即便如此,在 677 字符的测试文本下,依然基本可以控制在几十秒内完成,实际表现已经比较适合日常多人配音和剧本测试场景。
7.3 使用建议
如果你的主要需求是:
单人朗读
快速测试文本
短内容试听或克隆
那么优先使用 语音克隆模式,速度会更快。
如果你的需求是:
多人对话
多角色配音
小说剧本生成
带字幕输出的多人配音流程
那么使用 剧本工坊模式 会更合适,虽然耗时更长,但功能更完整。
图片预览
语音工作台 / 语音克隆界面


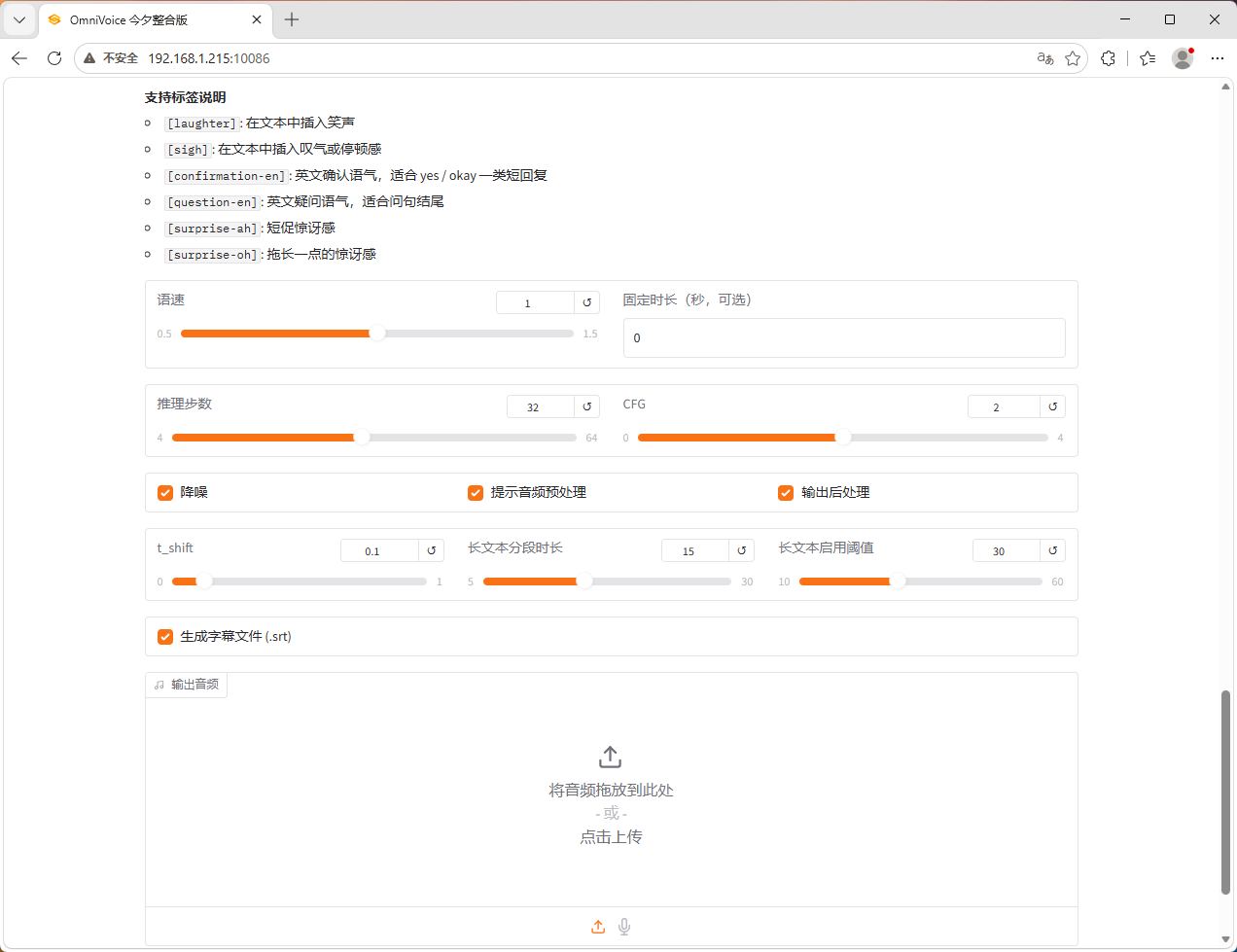
音色设计界面

剧本工坊 / 字幕配音 / 多人对话生成界面



音色库管理界面



多通道管理界面

阅读 APP 听书 API 对接界面
在线日志界面
下载地址
https://www.jxshn.com/downloads/zanzhujinxi
免费版本
免费版本功能也不少,可以先看看,也许你需要的功能刚好在免费版里就已经够用了。
https://www.jxshn.com/2061.html
在线版本免费体验

评论抢沙发