如果你想用今夕版在线 IndexTTS2 完成声音克隆、情感控制、LLM 接入、剧本整理,以及多人对话和多人小说配音生成,这篇图文教程可以直接带你从头走完整个流程。
本文会按照实际操作顺序,依次说明语音克隆、情感控制、DeepSeek 接入、剧本整理、剧本工坊、多人配音、多音字控制、试听与成品导出等功能。只要部署已经完成,照着下面的步骤操作,就可以较快跑通从文本整理到多人配音生成的完整流程。
1. 语音克隆功能使用图文教学
先点击这个链接进去部署 https://www.xiangongyun.com/image/detail/b8c5d270-8446-4d76-a445-0d19f66dc6b5?r=BFD7BU

当然 有可能是这样的 反正都差不多意思

并且选择配置确认部署
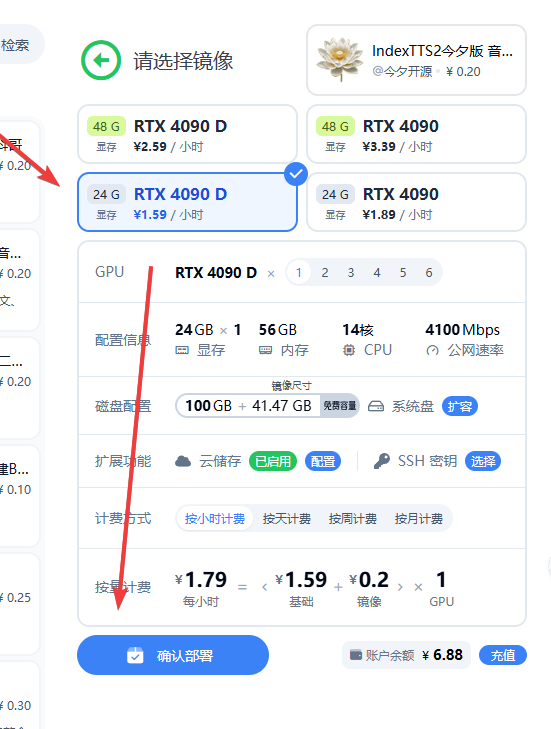
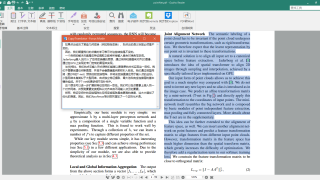
1.1 部署完成后,先点击 GPU 容器实例,界面如下图。
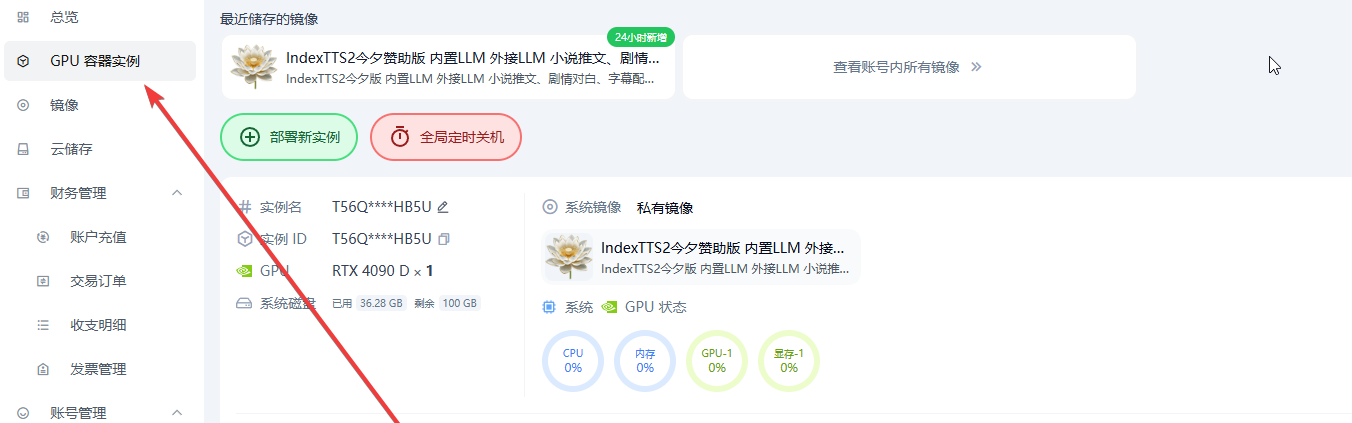
1.2 进入后,看右侧这两个菜单。主要操作入口是图中鼠标所指的 WebUI 主控台,点击后进入主要操作台。
1.3 这时会弹出操作网页。系统自带了不少音色,如果你想直接使用音色库中的音色合成音频,只需要在左下角选择音色,并在页面底部填写需要合成的文本即可。如果你想上传自己的参考音频,可以点击图中箭头所指的按钮,取消使用音色库音频。
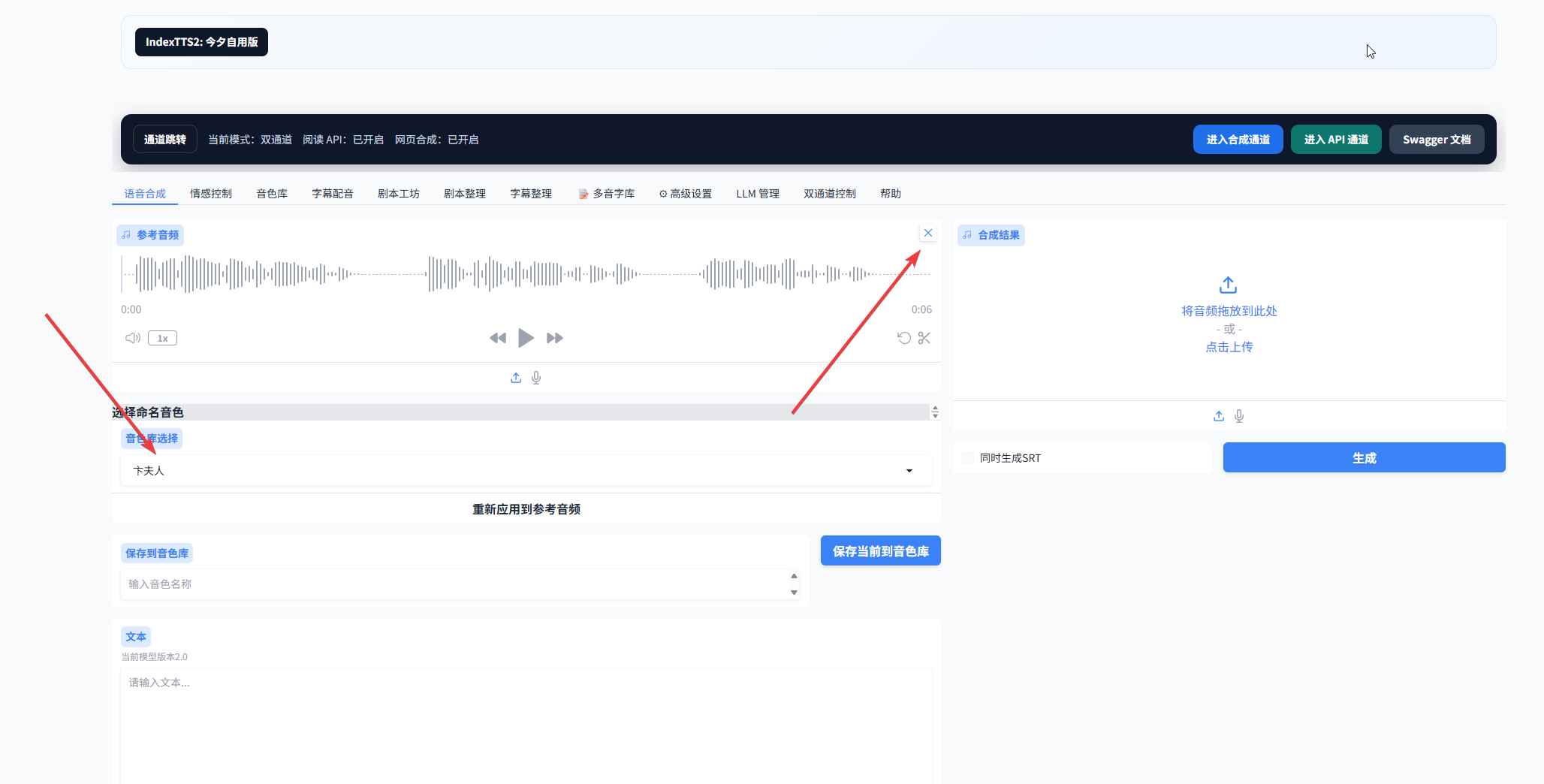
1.4 点击后会出现上传按钮,如下图。这时你可以上传参考音频,并填写克隆文本,同时决定是否生成字幕文件,以及是否将该音频保存到在线音色库中。如果要保存到音色库,需要补充音色名称。
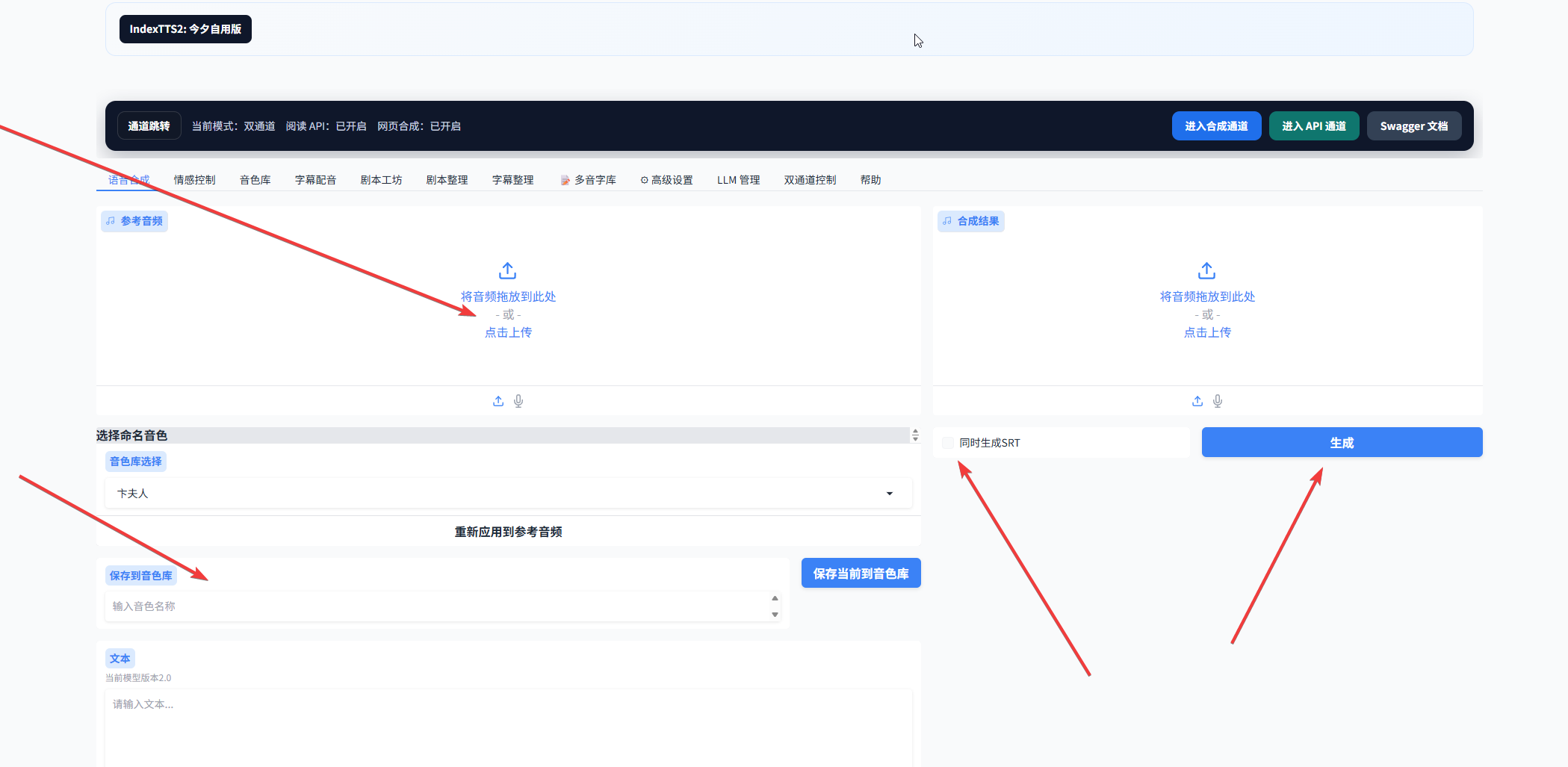
1.5 最后点击生成按钮,即可得到所需音频。生成完成后,点击箭头所指位置,可以分别下载音频文件和字幕文件。
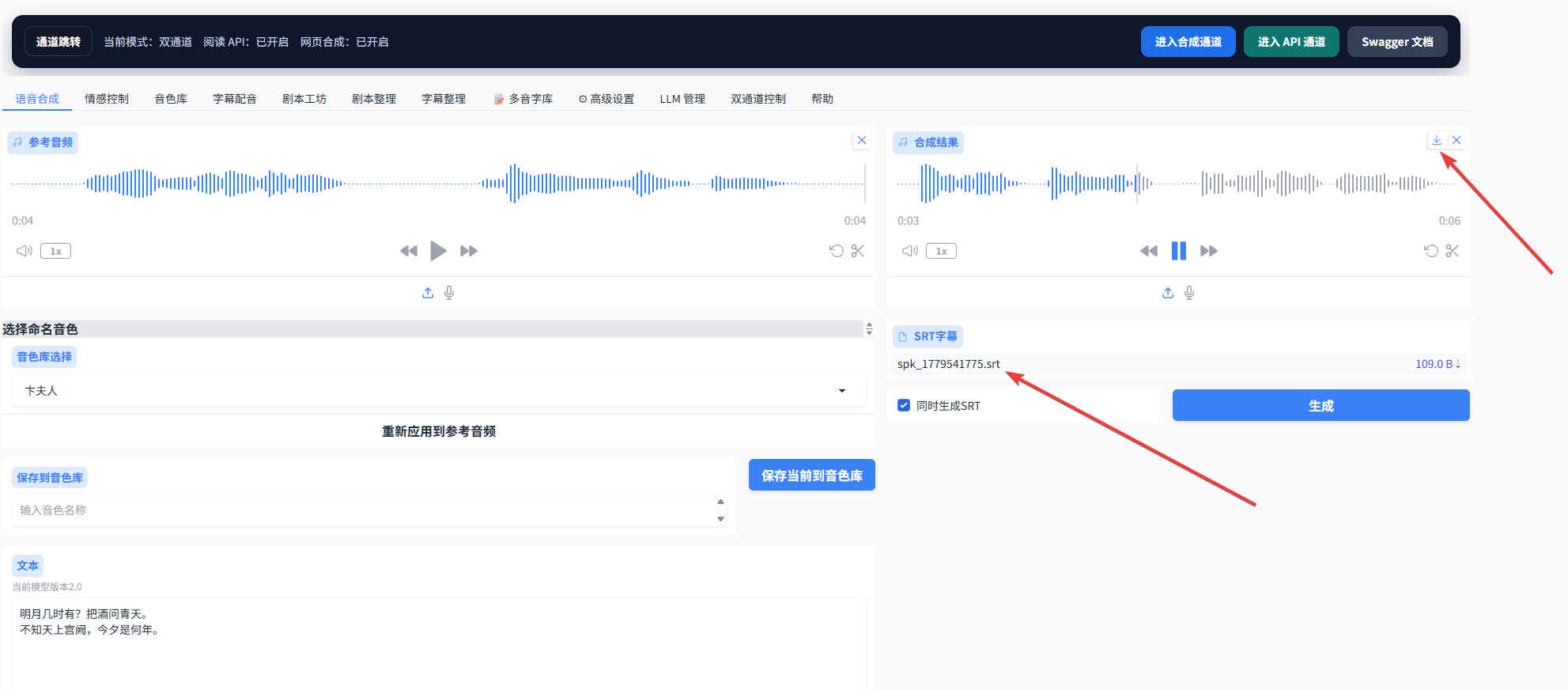
2. 情感控制功能使用说明
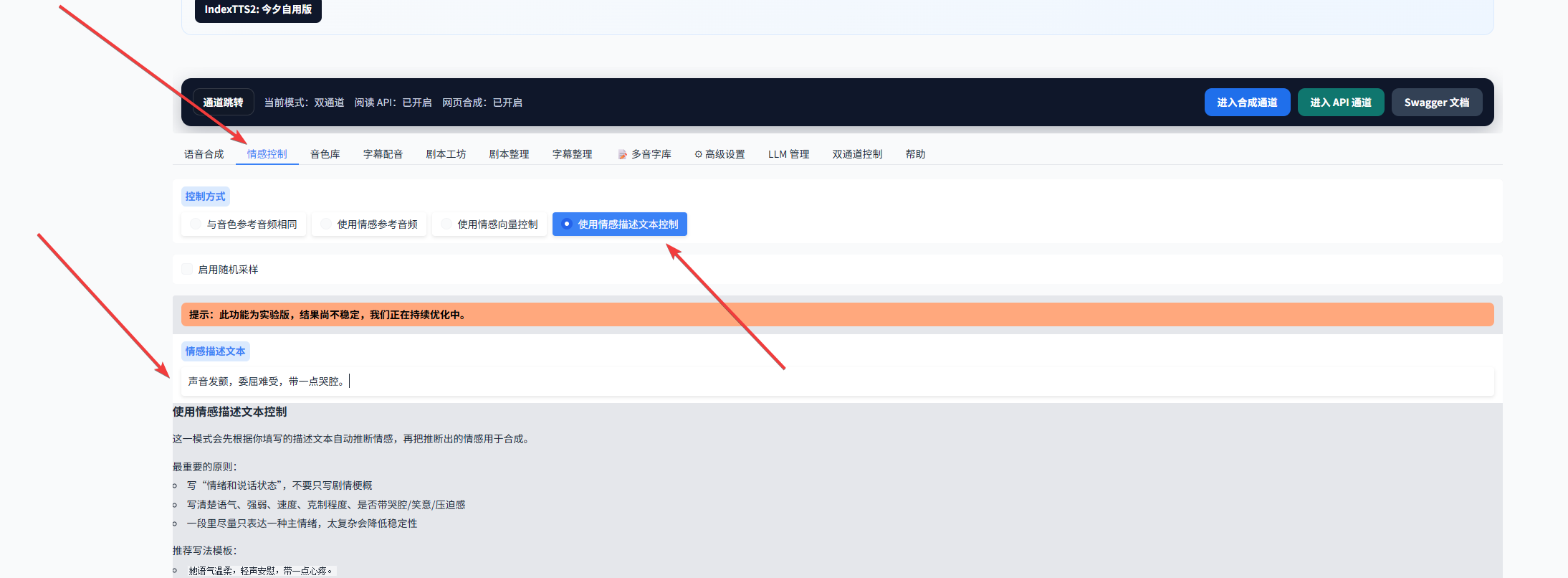
情感控制的整体操作流程和步骤 1 基本一致,只是需要额外进入情感控制面板。如下图所示,先选择情感控制方式,再切换回语音合成页面,点击合成即可得到带情绪变化的声音效果。
细心一点可以发现,这里一共提供了四种情感控制方式。建议都试一遍,找到更适合自己项目的模式。需要注意的是,这里的情感控制带有一定修正逻辑,所以有时情绪变化不会特别强烈。
如果你想要更明显的情绪表现,可以进入剧本工坊,把情绪强度模式切换为 加强。这个模式不做情感修正,表现会更直接。
3. 接入 LLM 大模型实现功能增强
今夕版在线 IndexTTS2 中有不少功能都依赖大模型支持,比较推荐接入 DeepSeek。虽然系统也自带 LLM,但实际表现相对一般,作为主力使用并不理想,因此更建议接入外部模型服务。
这里先简单说明一下界面中提到的功能逻辑:
当前已接入外接 LLM 的位置包括:台词情绪自动匹配、角色音色匹配模式、剧本整理、字幕整理。
当前已接入内置本地模型 / 本地 Qwen 的位置包括:台词情绪自动匹配、角色音色匹配模式、剧本整理、字幕整理。
当你把台词情绪自动匹配设置为自带 LLM 匹配时,点击分析台词情绪,程序会直接调用内置 QwenEmotion;如果设置为深度模式,则会调用你配置的外接 LLM。角色音色自动匹配、剧本整理和字幕整理也是同理。
系统目前已经内置了 DeepSeek、Moonshot、硅基流动、OpenRouter、Ollama 等常见预设;如果你直接粘贴这些服务的常用接口地址,页面通常也能自动识别。
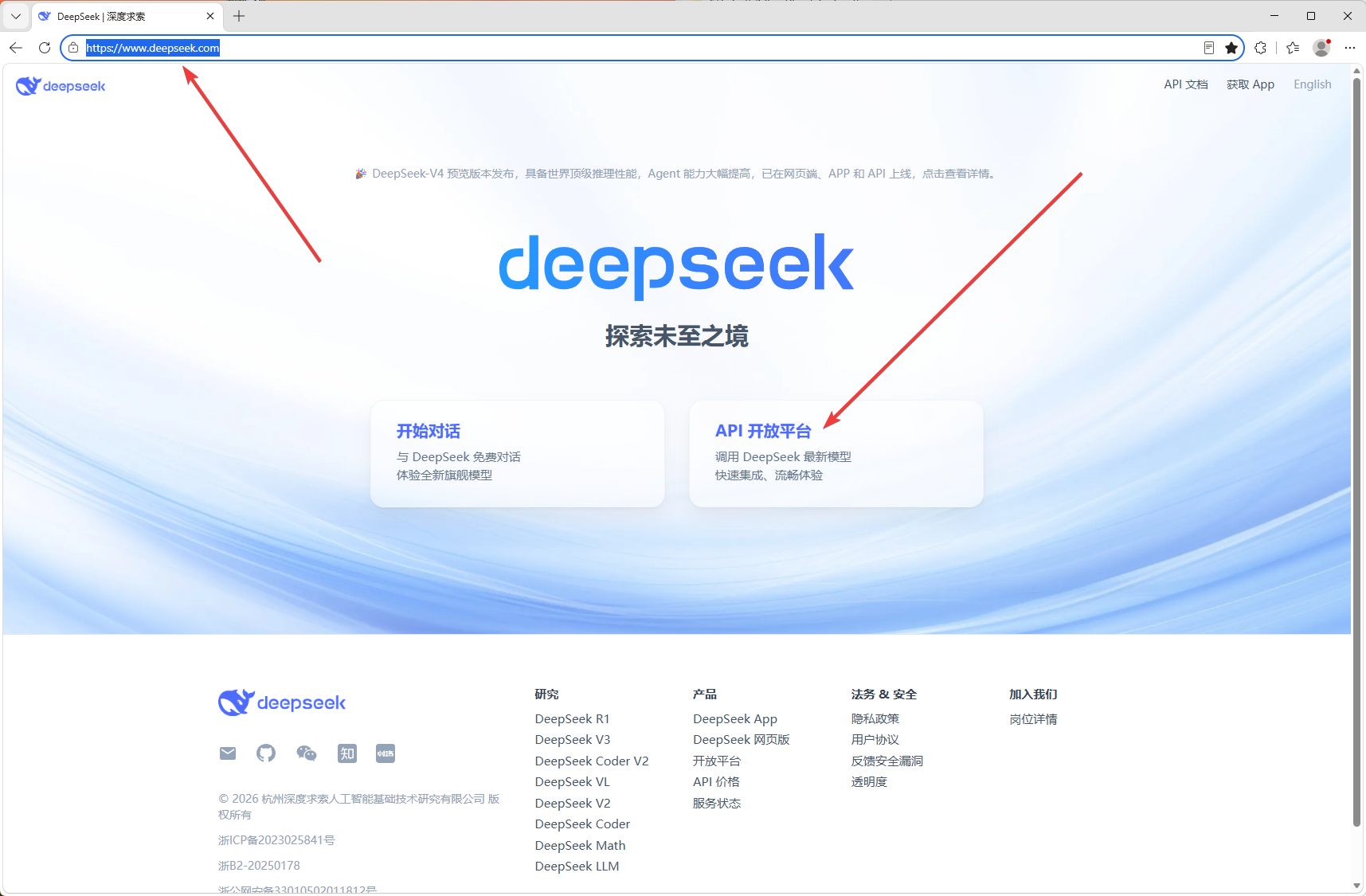
3.1 先进入 DeepSeek 官方平台,并选择 API 开放平台。
3.2 确认账户中是否有余额。如果没有,需要先充值。通常充值 1 元就能使用很久,有余额的话可以直接跳过这一步。
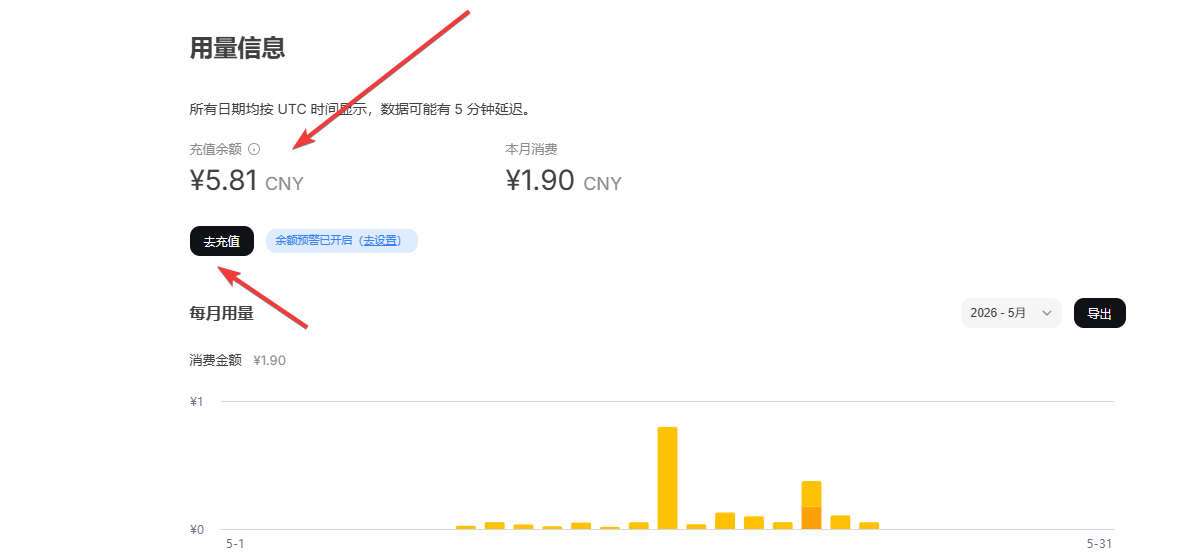
3.3 充值时需要选择自定义金额,这样才能充值 1 元。
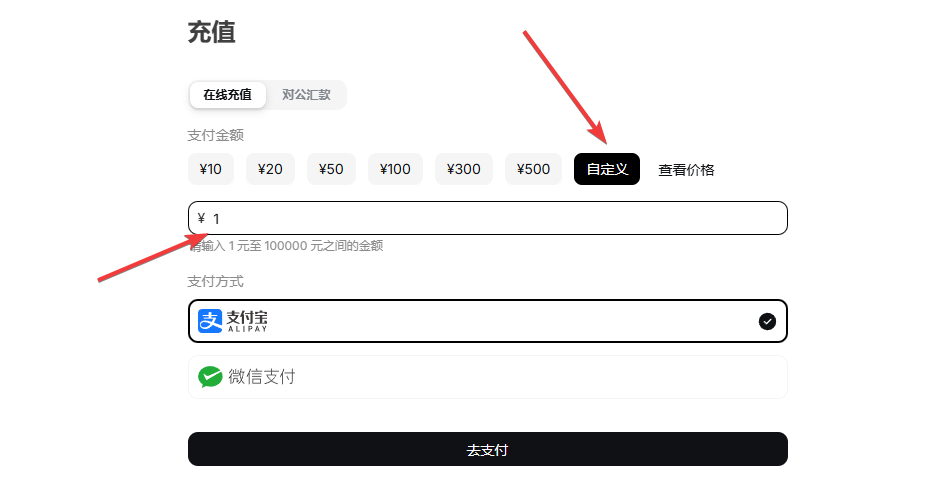
3.4 接着创建 API Key。点击左侧的 API keys 菜单,然后在右侧页面中选择创建 API Key,名称可以随意填写。

3.5 API Key 生成后,先保存到本地,同时复制到配音平台的 LLM 管理界面。注意,这个窗口关闭后通常无法再次查看原始 Key,只能删除后重新生成。
3.6 回到配音平台,点击 LLM 管理,服务类型选择 DeepSeek,然后把 API Key 粘贴到图中箭头所指的位置。
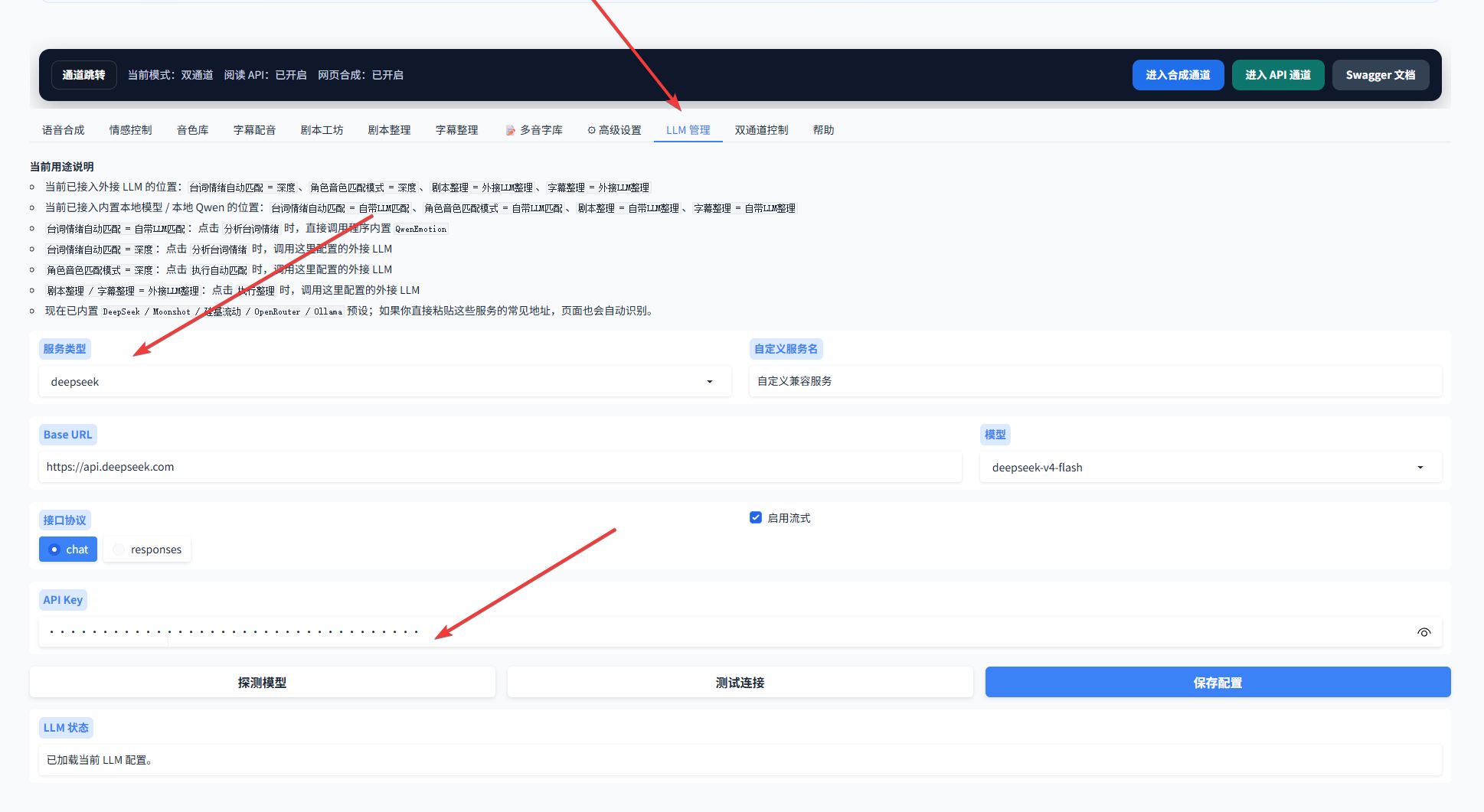
3.7 最后点击测试连接,确认没有问题后再保存配置。
4. 剧本整理功能使用方法
剧本整理的作用,是把普通小说文本整理成剧本中心可以直接支持的格式。这个功能依赖 LLM,如果还没有完成配置,请先返回步骤 3 完成设置。
点击剧本整理后,可以上传小说原文,或者直接粘贴到下方文本框中。然后选择整理方式,这里更推荐使用 全文外接 LLM 整理 或 在线整理。推荐星级越高,通常越值得优先尝试。下面以全文外接 LLM 整理为例。
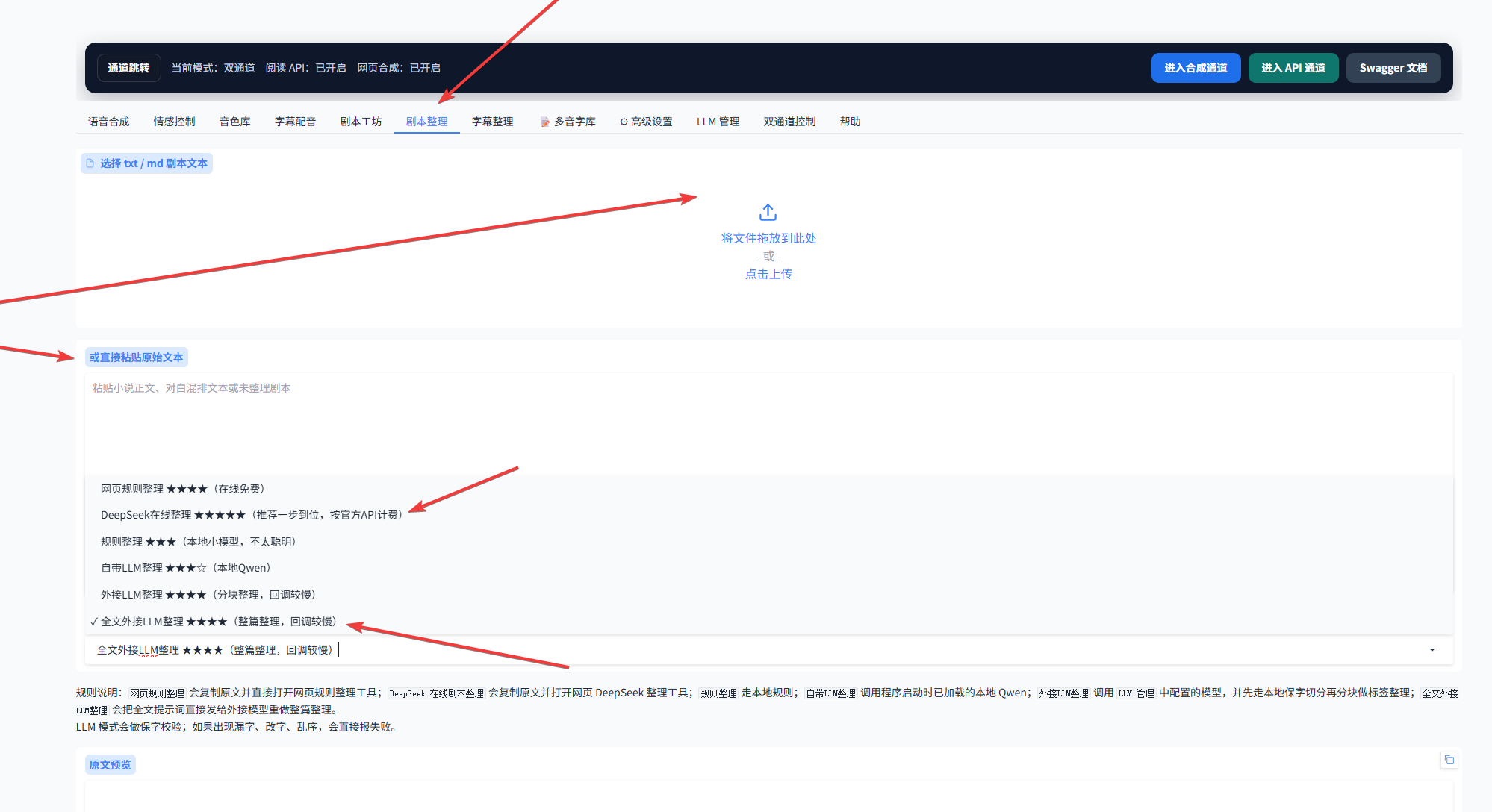
4.1 上传文本并选好模式后,点击执行整理即可。
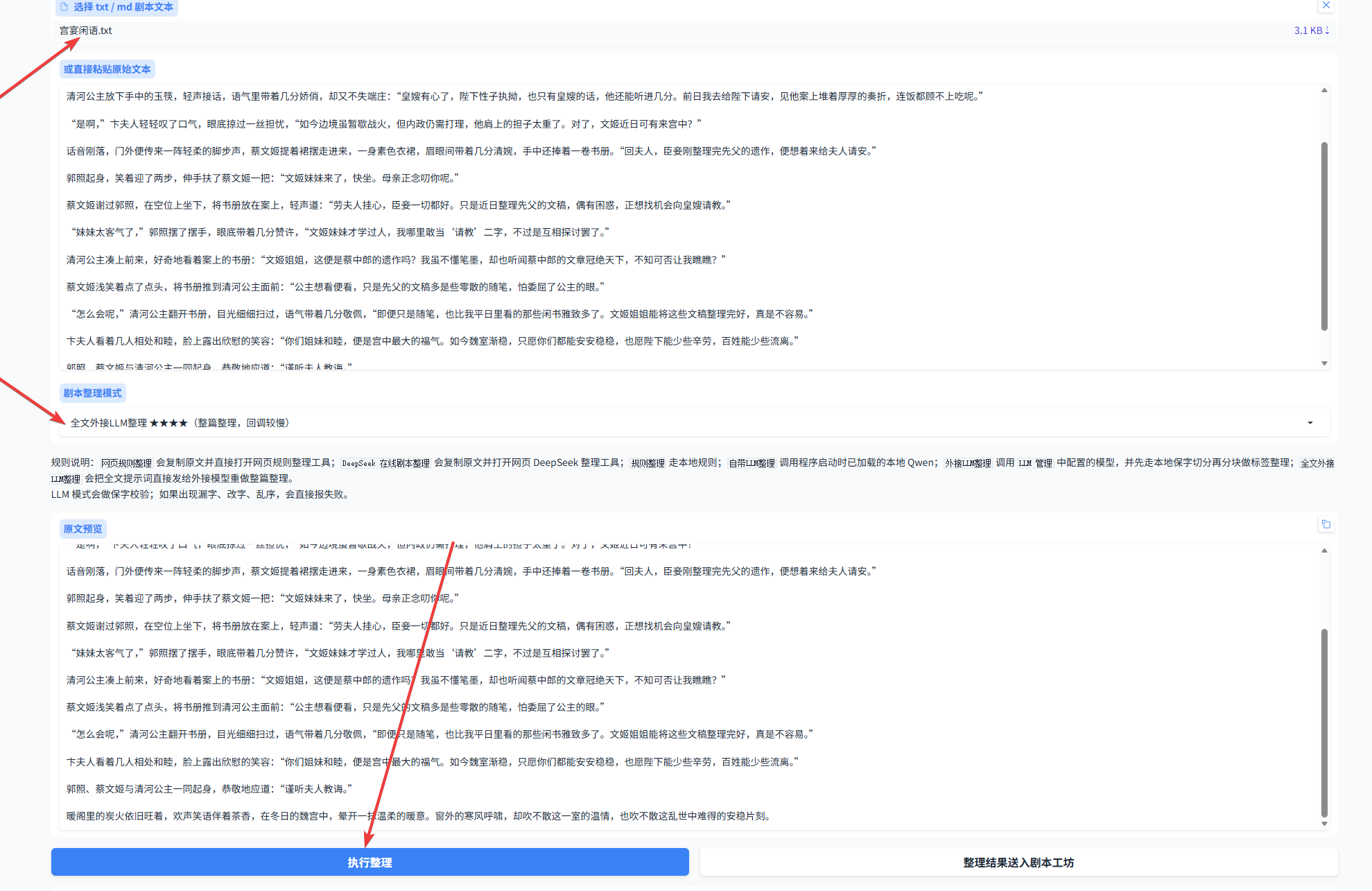
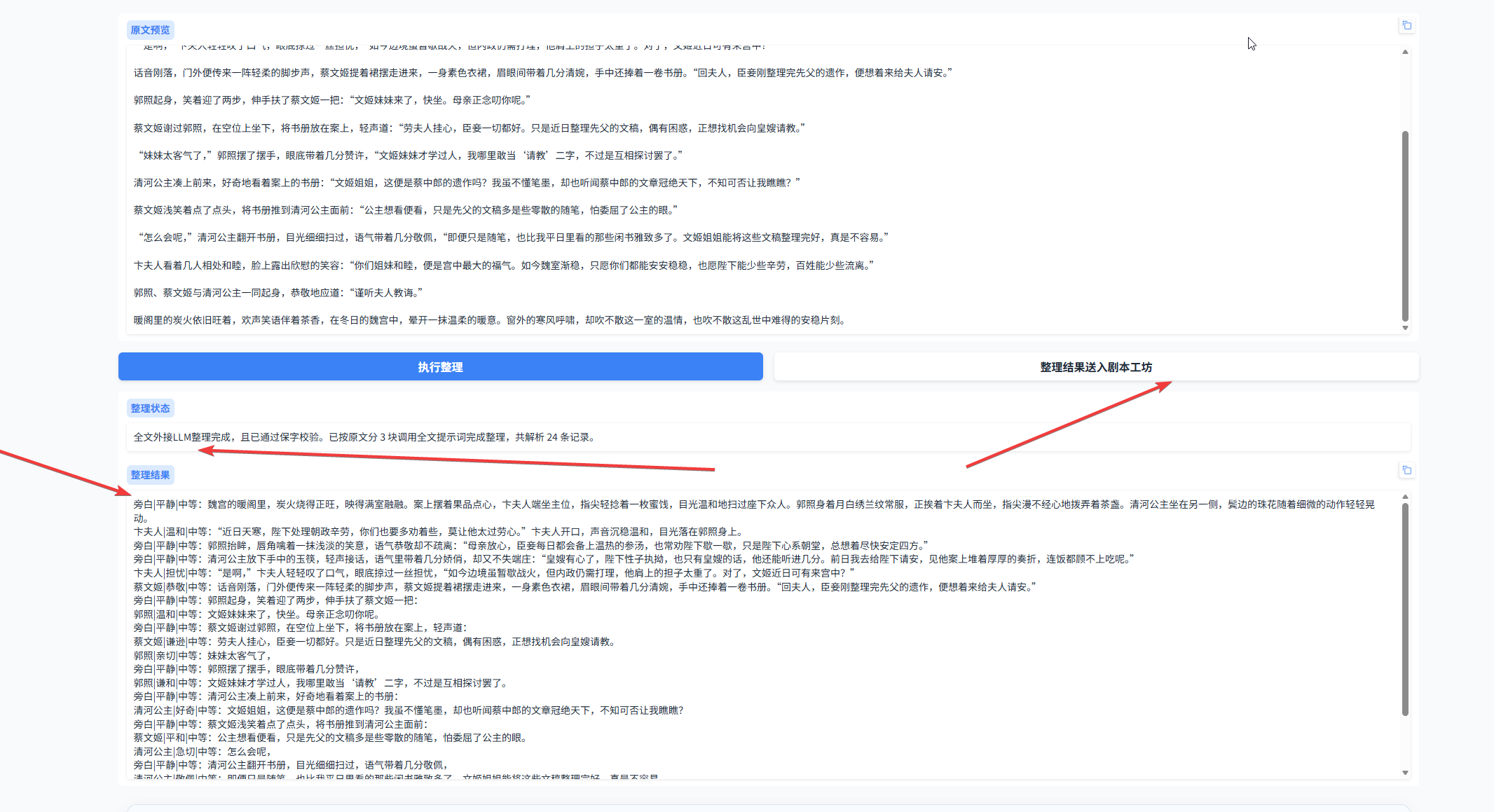
4.2 整理完成后,可以把整理后的剧本和原文进行对比。确认没问题后,点击 送进剧本工坊,就可以继续下一步的多人配音流程。
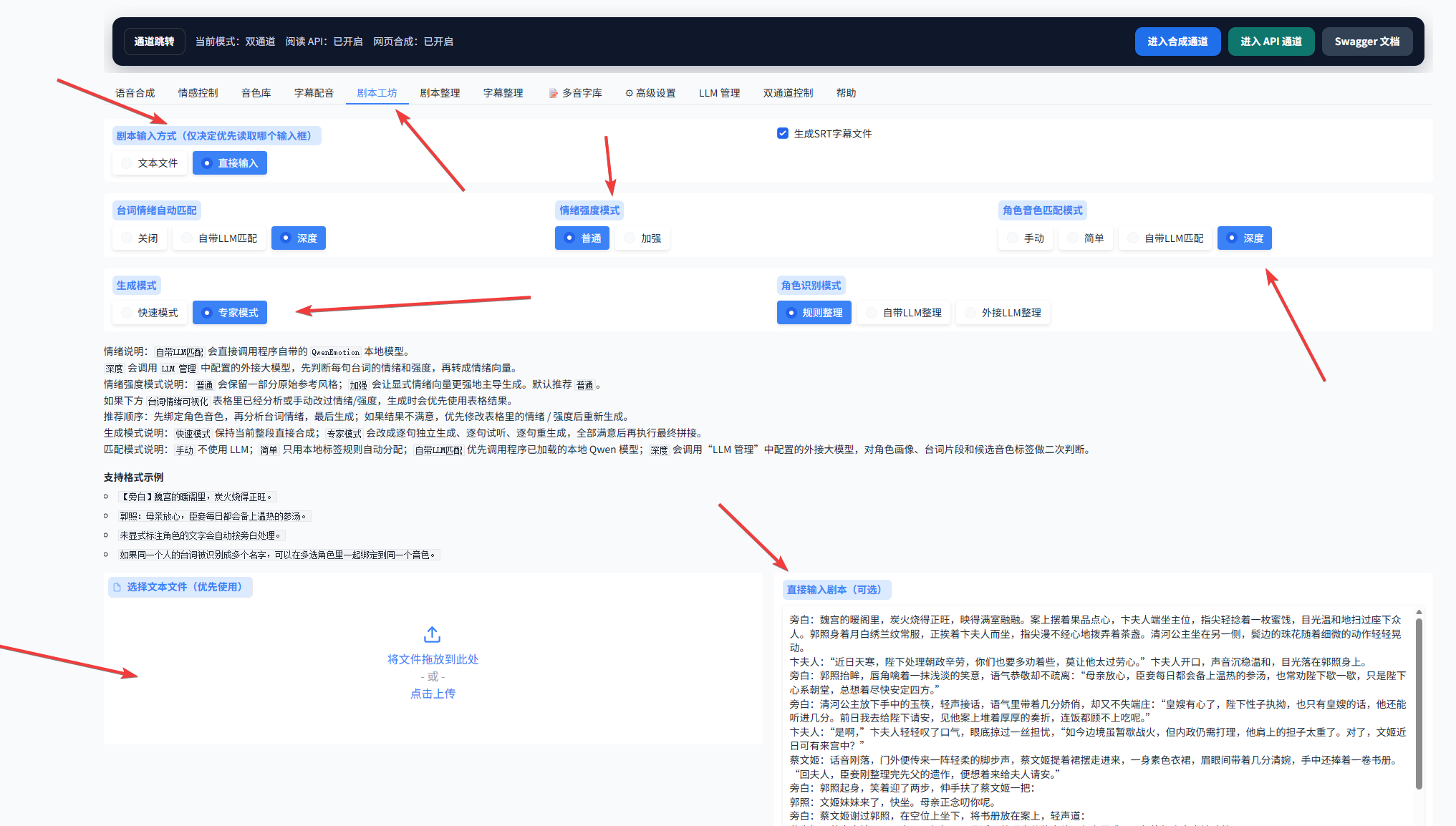
5. 剧本工坊与多人对话配音功能
5.1 先看一下剧本工坊界面。这里的设置项比较多,后续可以自行慢慢研究。一般来说,专家模式对应的是外接 LLM,例如 DeepSeek;自带 LLM 则是内置小模型,智能水平相对低一些,不建议当作主力使用。新手阶段大多数设置保持默认即可。
5.2 接下来是绑定音色。系统会自动识别出多个角色,你可以手动为每个角色逐一绑定音色。
如果需要上传自己的音色,可以切换到音色库界面进行上传。如果想使用自动匹配功能,需要先在音色库中给上传的音色打标签,例如男、女、年轻、成熟等。自动匹配会根据这些标签分配更合适的角色音色。
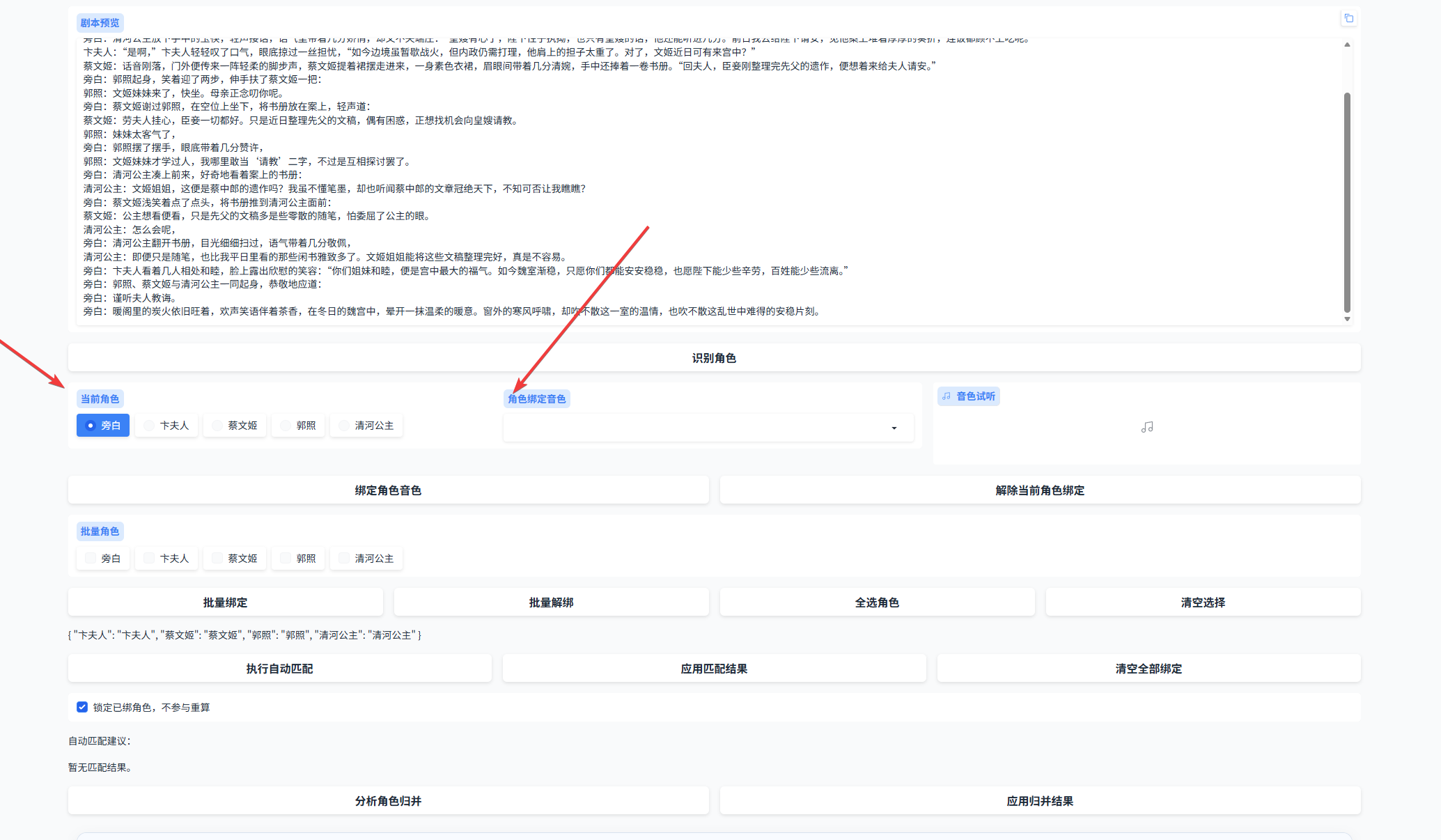
5.3 绑定完成后会显示如下图。如果你选择的是自动匹配方式,需要点击 应用匹配结果,绑定才会正式生效。
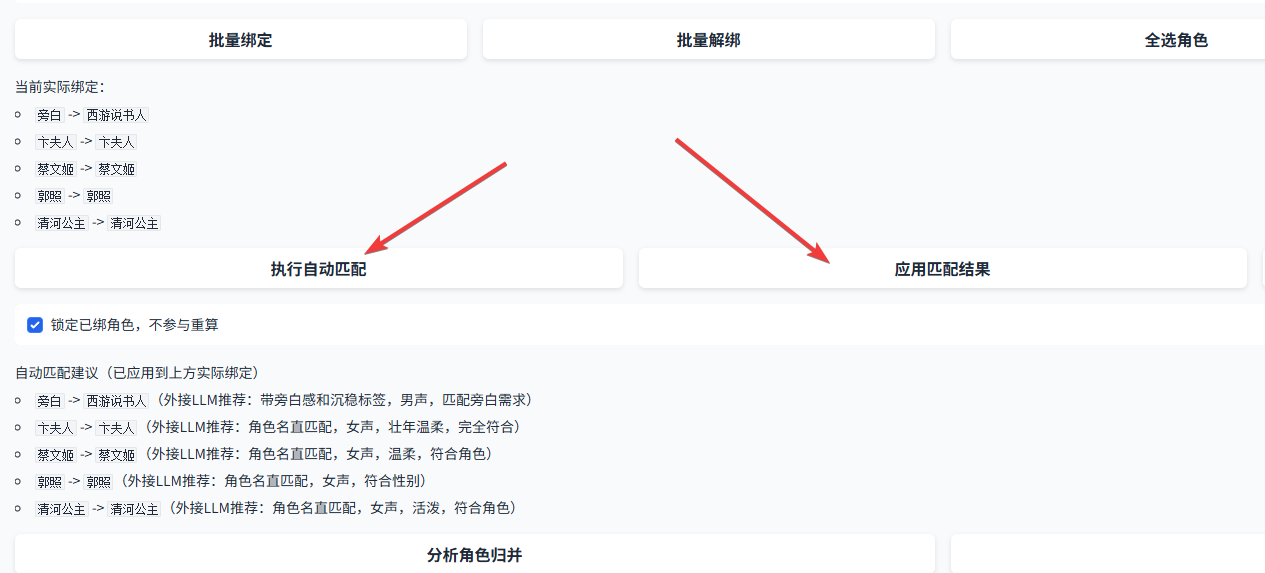
5.4 音色绑定完成后,就可以分析情绪了。点击 分析台词情绪 按钮进行匹配。需要注意的是,如果你使用的是五星推荐的匹配方式,有些模式本身可以继承情绪,这一步可以视情况跳过。
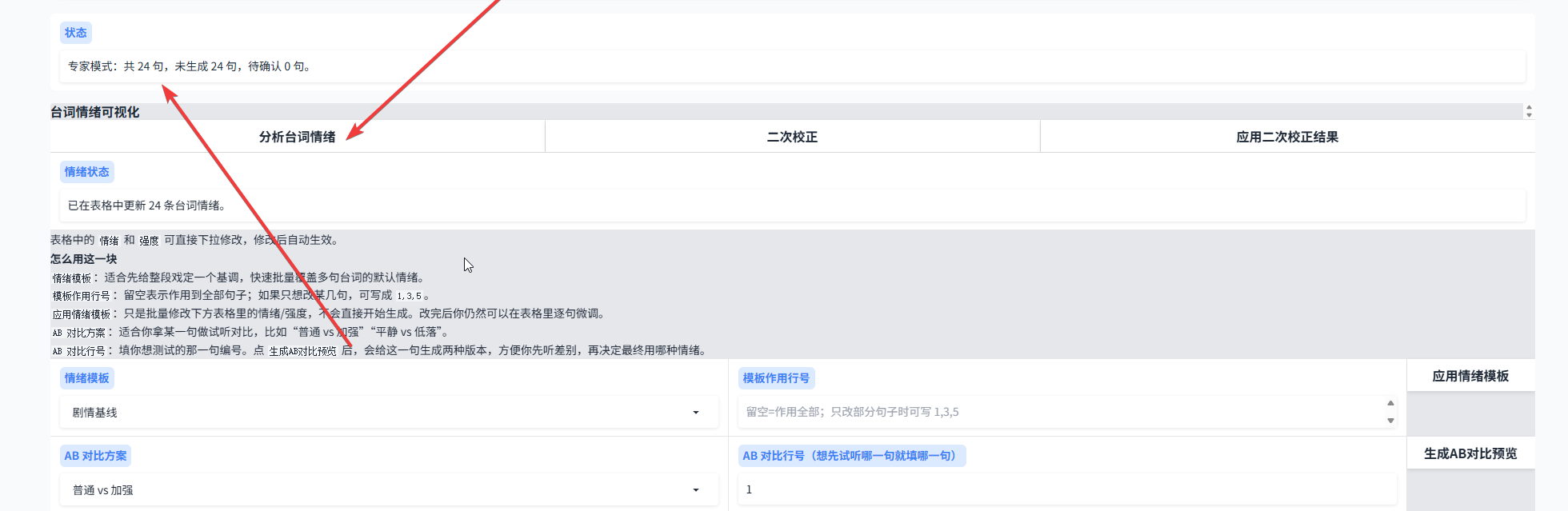
5.5 情绪分析完成后,下拉到专家模式工作台。这里可以单句生成,也可以批量逐句生成,同时支持前插台词、后插台词等操作。
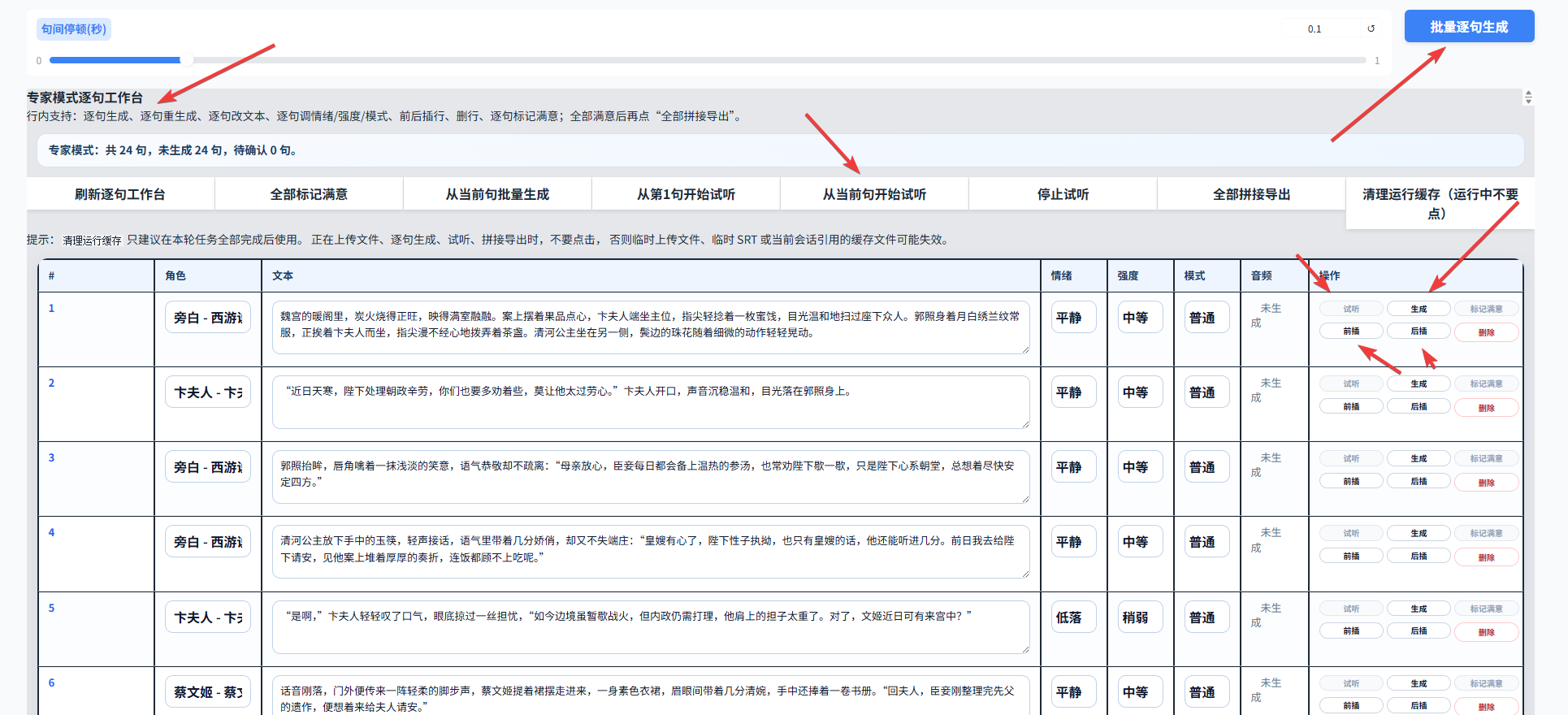
5.6 如果某句台词归属角色不对,也可以手动修改台词对应角色。
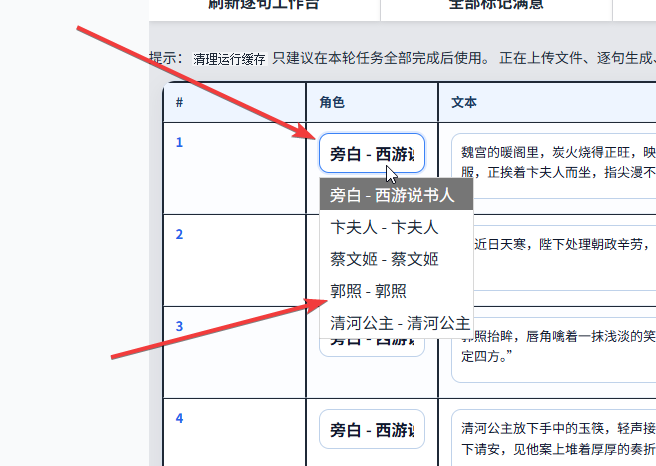
5.7 如果需要进一步调整情绪,可以修改情绪强度和情绪模式。这里的 加强模式,就是不做修正的情感控制方式,整体表现会更直接。
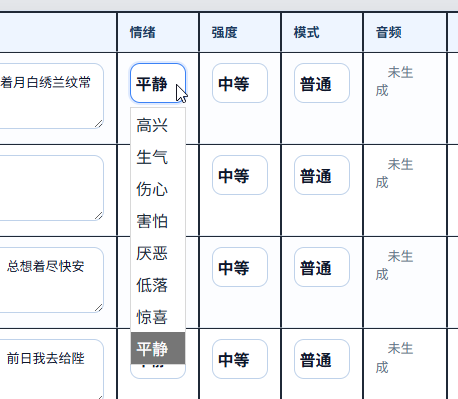
5.8 下面说一下插入台词和多音字控制。
先插入一行台词。比如下面这个例子里有两个“倒”字,它们的读音分别是三声和四声,这时就需要手动做读音控制。

处理方式也很简单,直接按下图这样为多音字标注读音,就可以实现多音字控制。

5.9 试听功能也需要说明一下。这个功能目前有一点小问题:如果音频生成完后,点击“从第一句开始试听”,实际播放的可能不是第一句。
更稳妥的处理方法是:先停止试听,然后上拉到第一行,在第一行操作区域点击试听,再点击“从当前句开始试听”。这样通常更准确。
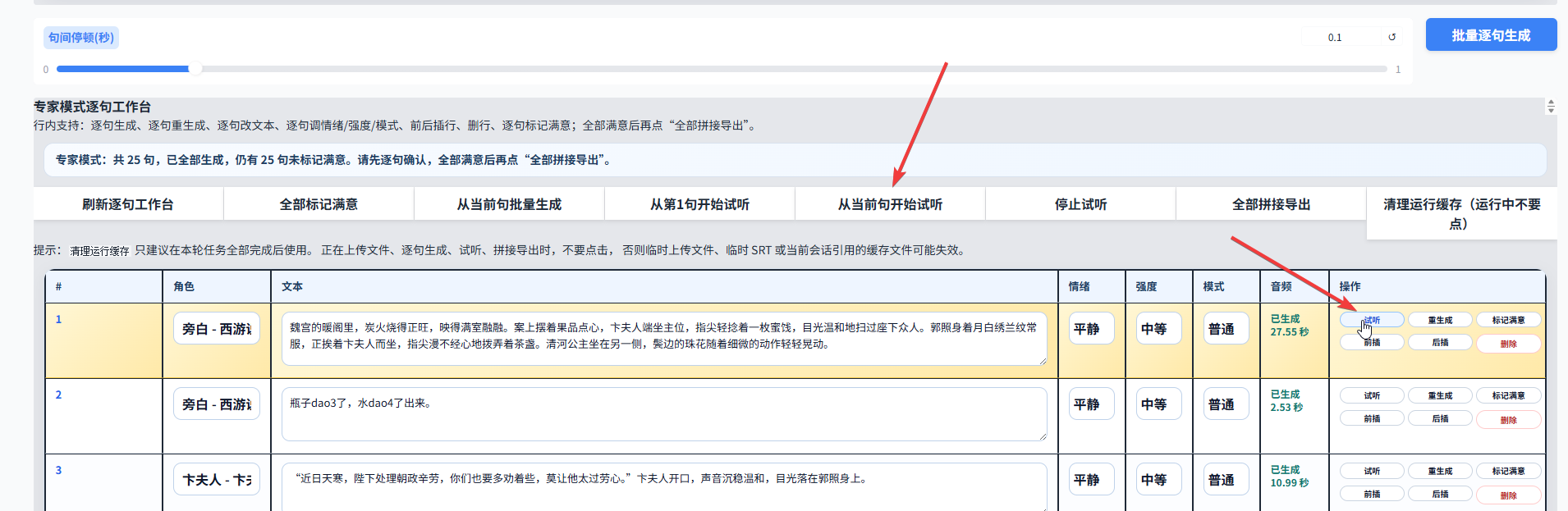
5.10 所有台词生成满意之后,就可以开始拼接音频。需要注意的是,所有台词都必须先被标记为满意,系统才允许最终合成。
操作方式如图所示,先点击 全部标记满意,再点击 全部拼接导出。然后下拉到页面底部,稍等一会儿,结果就会显示出来。
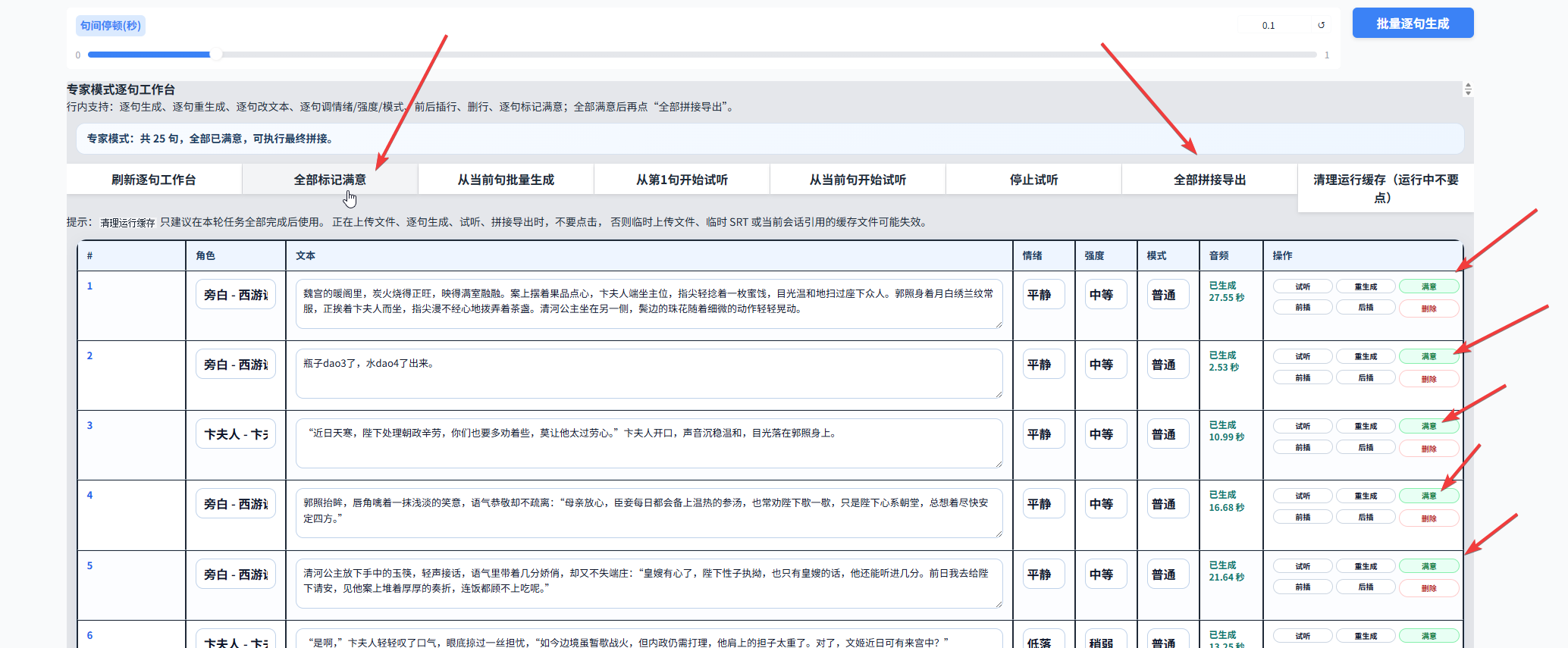
5.11 最后点击箭头所指位置,分别下载成品音频文件和字幕文件,到这里一次完整的多人配音流程就完成了。





评论抢沙发