简介说明
Qwen3-TTS 今夕整合版 支持多人小说配音 多人交谈 多人播客 预设音色、语音克隆、音色设计、阅读APP接入、字幕配音、字幕整理、发音覆盖与音色库管理
使用配置
1.推荐比较新的N卡使用,显卡占用8G,内存占用1.5G左右.(台式机5060ti)
2.旧版本N卡也能用,就是使用cpu+内存,也支持A卡I卡,但是需要比较大的内存,建议8-16G运行内存,由于各个内存的频率不同,
还是建议16G内存以上使用会更好。
3.使用CPU跑,有时候网页会出现红色的提示,那是因为模型超出了内存,关闭后重新打开软件即可。
更多介绍
Qwen3-TTS 今夕整合版 改动说明
================================
这份整合版是在官方 Qwen3-TTS 原版基础上,围绕“便携运行、中文网页控制、阅读接口、音色管理、字幕配音、微调辅助”做的二次整理。
一、和原版相比,核心改动了什么
--------------------------------
1. 改成了 Windows 便携整合包结构
- 临时文件、日志、输出文件都尽量收口到项目目录内
- 音色库放到项目内:jxshn-com/voice_library
- 目标是:换目录、换盘符后仍尽量可运行,不依赖系统全局路径
2. 改成单入口启动
- 默认只需要运行:启动.bat
- 不再要求分开记多个功能脚本
- 模型路径、功能切换、接口说明、阅读 API 都集中到网页里处理
- 已清理旧的分模型启动 bat 和单独下载模型 bat,减少重复入口
3. 加了环境检测和自动验证
- 环境检测.bat:检查发布包关键文件是否完整
- 启动.bat:启动整合版网页与阅读接口
- 停止.bat:关闭已启动的整合版进程
4. 自带 SoX 便携工具
- 已内置sox.exe
- 启动时会自动加入 PATH,减少错误 问题
5. 主界面重做为中文单入口控制台
- 状态页
- 阅读 API 页
- 预设音色
- 音色设计
- 语音克隆
- 先设计后克隆
- 音色库
- 字幕配音
- 微调向导 / 任务相关页
- 使用讲解页
二、比原版新增了哪些主要功能
----------------------------
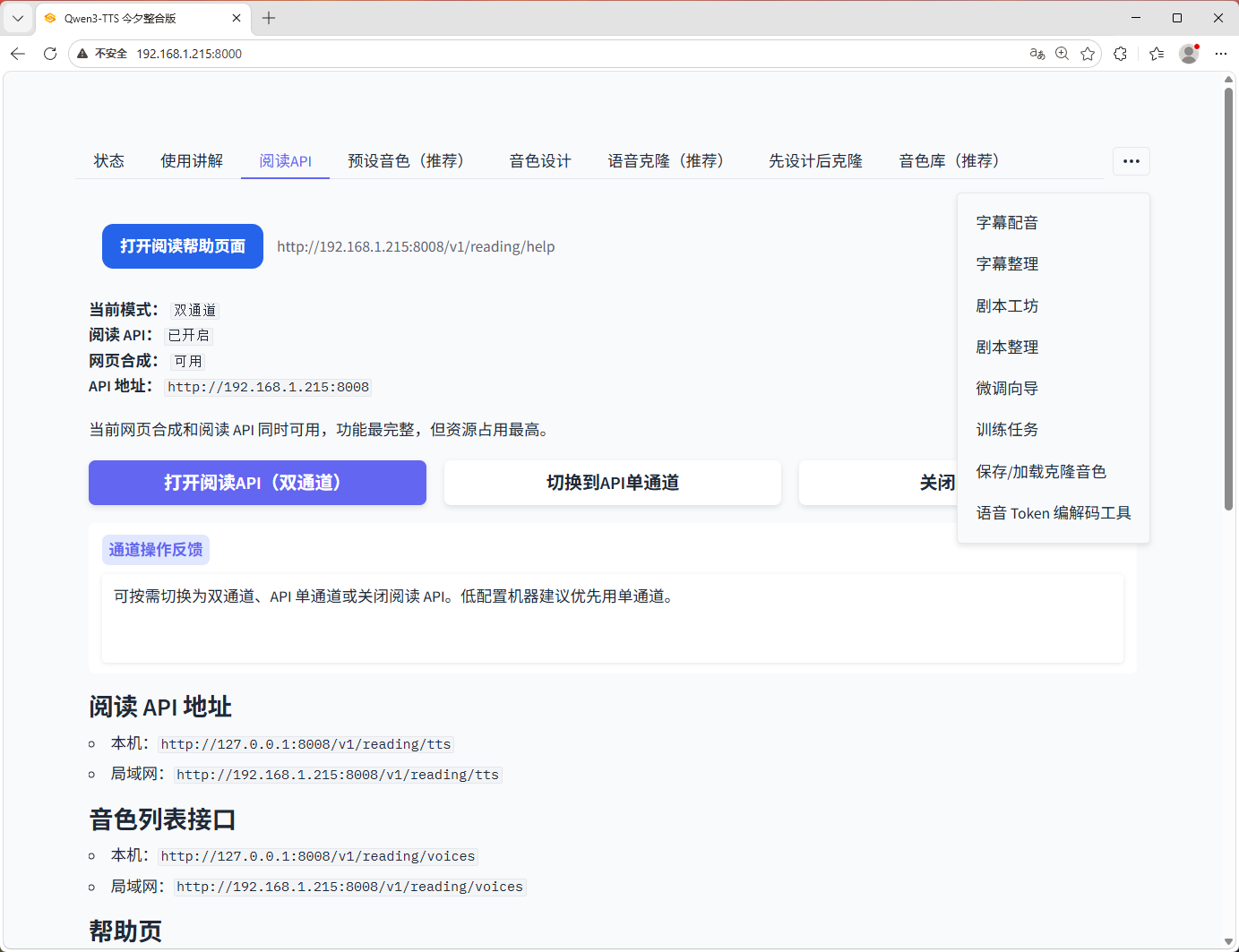
1. 阅读 API 扩展
- /v1/reading/tts 整段普通音频接口 - /v1/reading/tts_fast 阅读优化接口,默认推荐 - /v1/reading/tts_ultrafast 实验接口,当前实测不一定更快 - /v1/reading/tts_stream_wav 实验性 chunked wav 音频流接口,尽量接近流式阅读 - /v1/reading/tts_pseudo_stream SSE 伪流式接口,适合浏览器或支持 event-stream 的客户端 - /v1/reading/voices 返回音色库音色和预设说话人 - /v1/reading/help 阅读 API 在线帮助页 - /v1/reading/diag 诊断接口,返回切段、耗时、模式、音色命中情况 - /v1/reading/prewarm 预热模型接口,减少首次等待 - /v1/reading/status 返回阅读相关模型是否已热启动
2. 阅读 API 帮助页增强
- 在线测试
- 可出声接口下拉选择
- 阅读 APP 规则写法自动联动
- 预热模型按钮
- 流式兼容测试按钮
- 读取诊断信息按钮
- 流式兼容测试会自动尝试播放前几段已收到音频
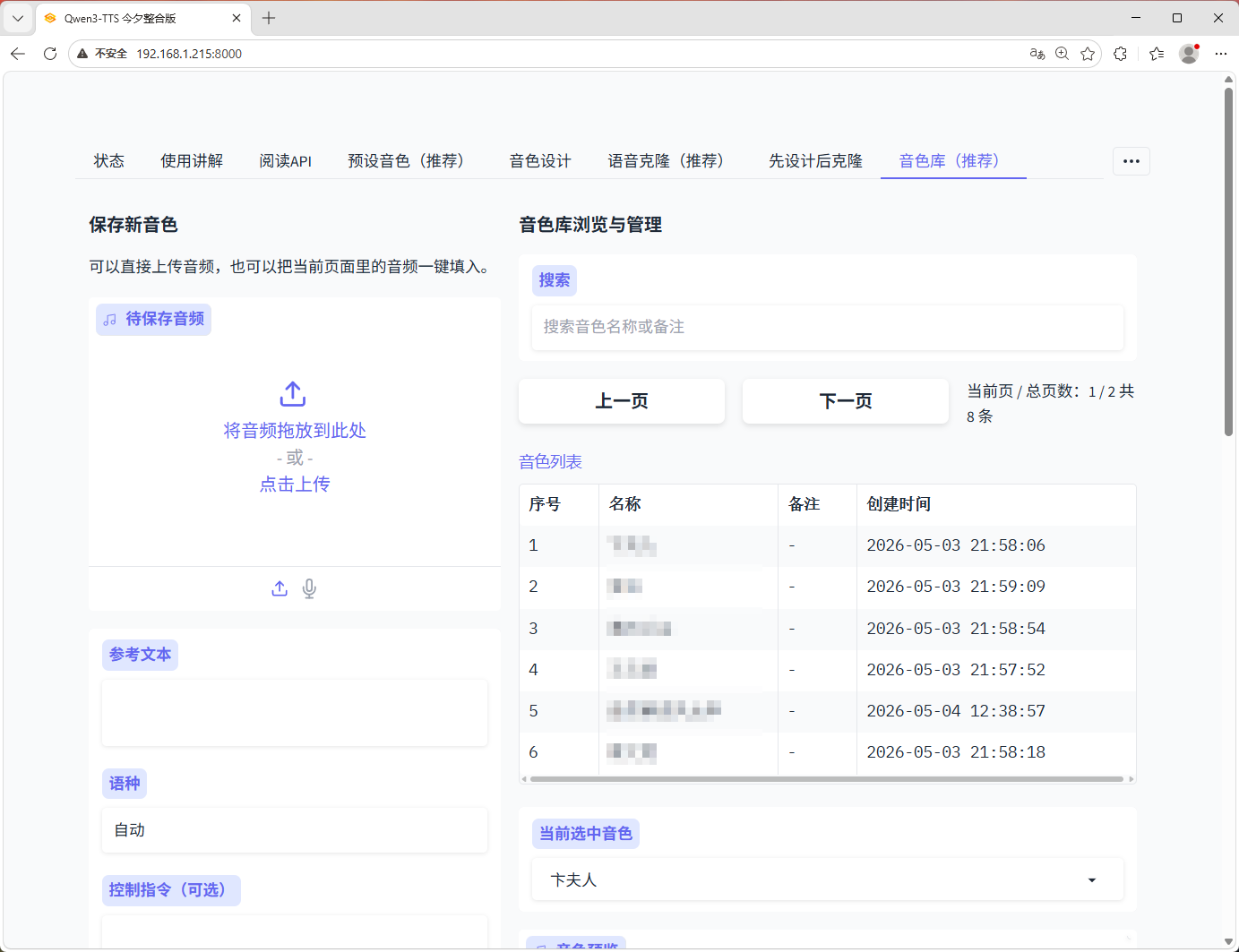
3. 音色库增强
- 保存音色
- 删除音色
- 重命名
- 编辑备注
- 分页、搜索、预览
- 一键应用到当前表单
- 一键应用到字幕默认音色
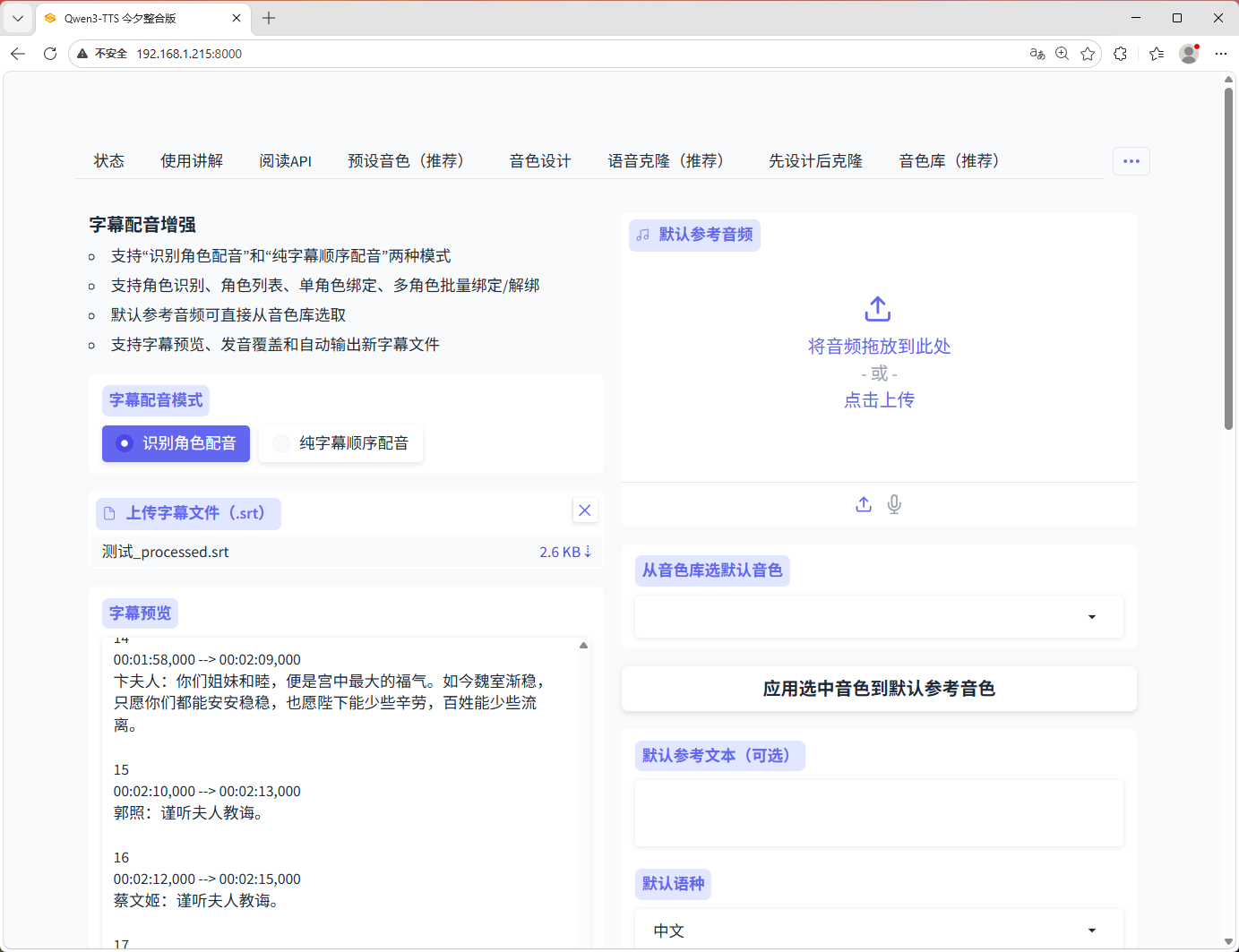
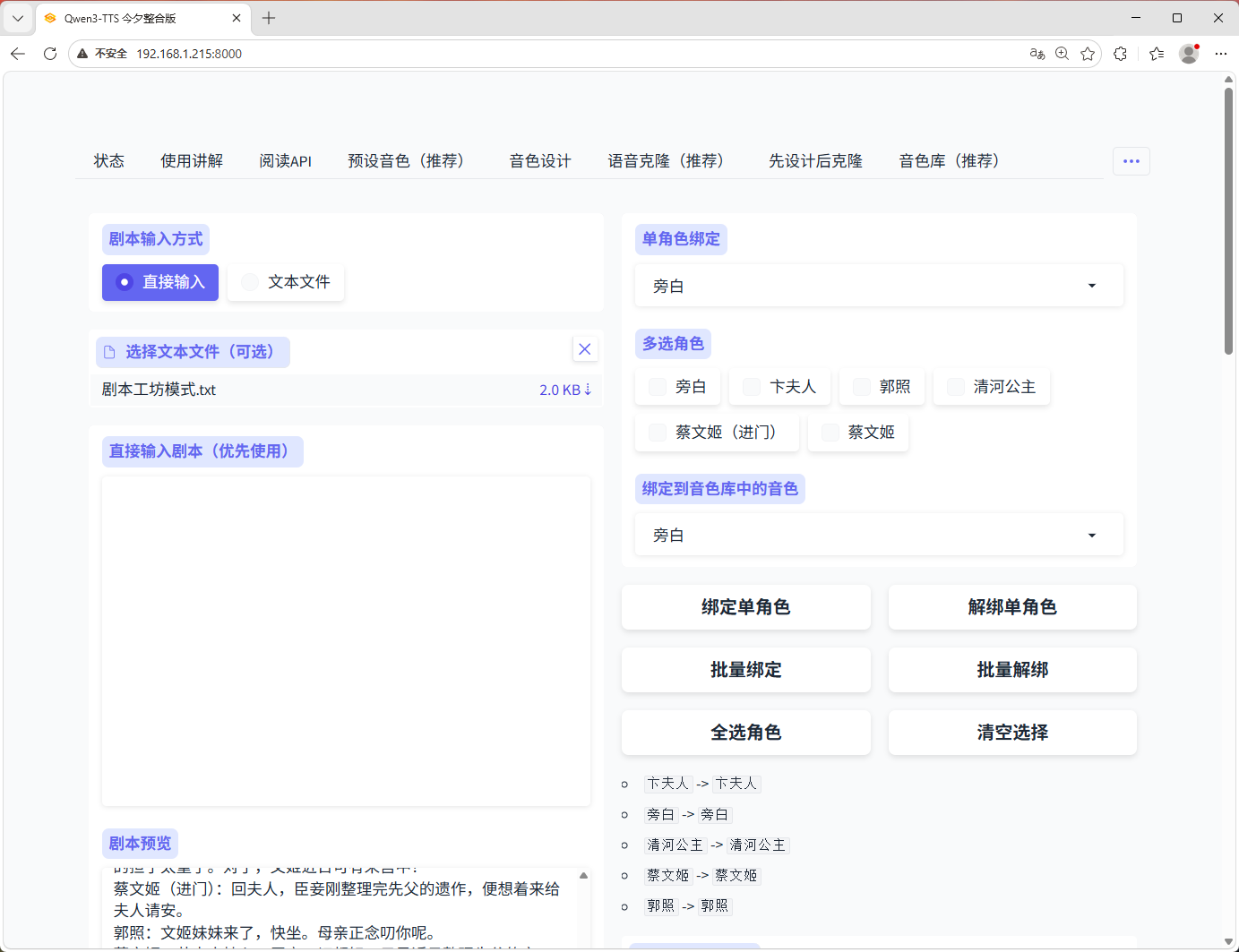
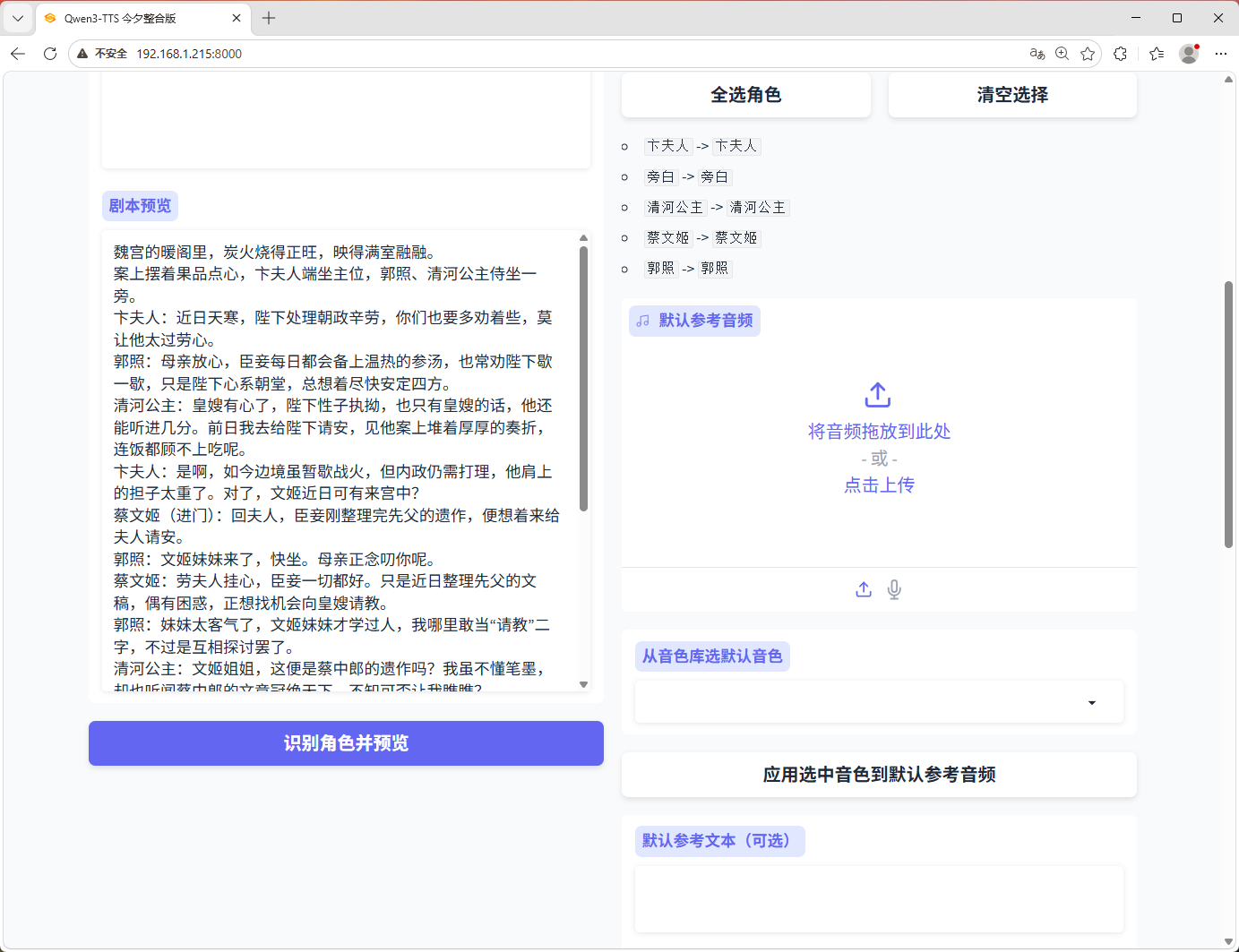
4. 字幕配音增强
- 识别角色配音
- 纯字幕顺序配音
- 角色列表展示
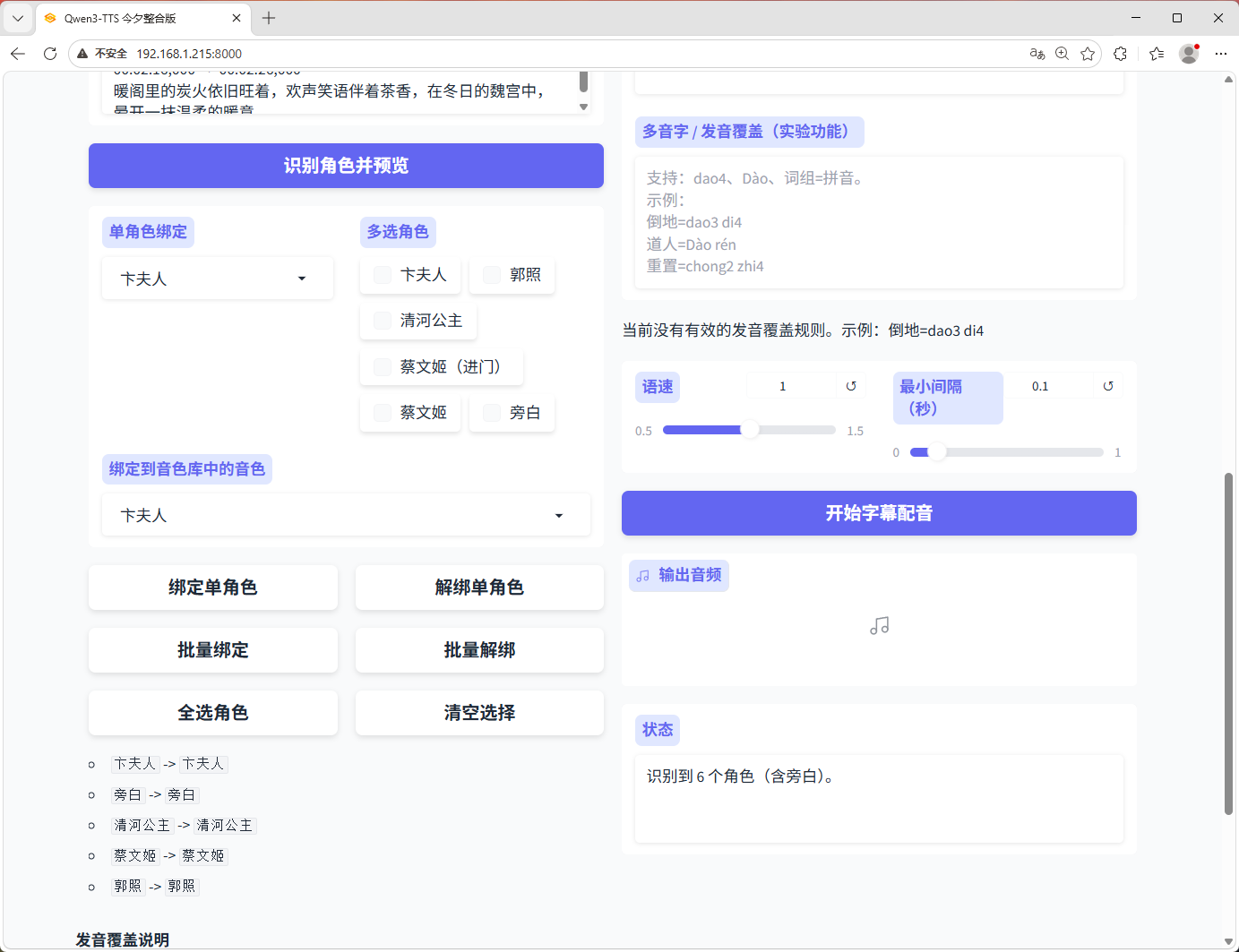
- 单角色绑定音色
- 多选角色批量绑定/解绑
- 全选角色、清空选择
- 默认参考音频直接从音色库选取
- 字幕预览
- 生成音频后自动输出字幕文件
5. 发音覆盖增强
- 页面中文化说明
- 支持多音字 / 词组级覆盖输入
- 支持 dao4、Dào 等输入样式
- 页面内提供示例说明
- 当前仍标为实验功能,不能保证所有情况都完全命中
6. 微调辅助增强
- 微调向导页
- 一键生成 train_raw.jsonl
- 一键扫描数据集
- 检查缺失 txt / 空文本 / 坏音频
- prepare_data.py 命令辅助
- 训练命令生成器
- 训练完成后可手动写回模型路径
7. 其它扩展
- 先设计后克隆
- 语音 Token 编解码工具
- 保存/加载 clone prompt
- 本地模型优先加载
- 阅读 API / 网页合成双通道、单通道切换
三、对官方原始网页 Demo 的界面改动
----------------------------------
1. 中文化
- 主界面主要功能改成中文说明
- 保留少量必要英文参数名,便于对照官方文档
2. 结构重组
- 统一入口,不再分散成多个页面启动
- 状态页集中显示模型、设备、接口、热启动状态
- 阅读 API 页单独整理成面对阅读 App 的说明区
3. 新手引导
- 新手推荐流程
- 常用页签前置
- 推荐功能标记
- 使用讲解压缩为更偏上手导向的说明
四、当前默认推荐怎么用
--------------------
1. 普通合成
- 预设说话人:用“预设音色”页
- 语音克隆:用“语音克隆”页
- 设计音色:用“音色设计”页
2. 阅读接口
- 默认推荐:/v1/reading/tts_fast - 如果客户端支持持续播放流:试 /v1/reading/tts_stream_wav - 不建议默认把 /v1/reading/tts_ultrafast 当作最快接口,因为当前环境里实测并不稳定
3. 阅读页推荐步骤
- 第 1 步:先点“预热模型”
- 第 2 步:点“流式兼容测试”或“读取诊断信息”
- 第 3 步:再正式使用阅读接口
五、目前已知限制
----------------
1. 官方本地 Python 推理接口并不等于完整低延迟实时云端接口
- 已尽量做接近流式的本地阅读方案
- 但是否能真正“边收边播”,还取决于阅读 App 是否支持持续音频流
2. tts_ultrafast 只是实验接口名
- 当前整合环境里不保证实测最快
- 默认还是优先推荐 tts_fast
3. 发音覆盖仍是实验功能
- 某些复杂上下文、多音字歧义、模型内部语义偏置,仍可能影响结果
4. 克隆音色通常比预设说话人慢
- 想要更快的阅读速度,优先考虑 custom 预设说话人
六、建议
--------
如果你的目标是“尽量流式阅读”,推荐优先按下面顺序尝试:
1. 先预热模型
2. 先用预设说话人,不要先上克隆音色
3. 阅读接口优先试 tts_fast
4. 如果客户端支持持续播放,再试 tts_stream_wav
5. 如果阅读 App 不支持持续播放,只能退回普通音频接口或考虑更换客户端
七、2026-04-29 兼容性修复
-------------------------
1. 修复便携 Python 仍可能引用外部环境的问题
- 当前发布版不要求用户单独操作项目内 Python
2. 增加启动兼容性处理
- 对设备与依赖相关的启动问题做过兼容性整理
- 目标是减少因环境差异导致的直接崩溃
3. 调整语音克隆默认选项
- 语音克隆页“仅用说话人向量(效果有限,但不用填写参考音频文本)”默认勾选
- 保存音色文件区域同名选项也默认勾选
- 这样新手只上传参考音频时不容易因为忘填参考文本而失败
八、2026-05-03 发布与便携修复
-----------------------------
1. 修复音色库搬迁后失效的问题
- 目录改名、换盘符、整体复制后,音色库应继续可见
2. 修复字幕配音缺少参考文本时报错
- Base 语音克隆在没有参考文本时,会自动走 `x_vector_only_mode=True`
- 不再因为空 `ref_text` 直接报:
`ValueError: ref_text is required when x_vector_only_mode=False`
3. 修复打包资源缺失
- 已补齐 `gradio`、`groovy` 等运行资源
- 不再依赖外部手工补 `blocks_events.py`、`version.txt` 这类文件
4. 补充旧显卡自动回退保护
- 现在不只是 `device=auto`,即使手动写了 `cuda` 或 `cuda:0`,启动前也会先做 CUDA 兼容性检测
- 如果检测到显卡算力低于 7.0,例如 GTX 1050 这类 `sm_61` 老显卡,会直接回退到 CPU 模式
- 如果 CUDA 设备索引无效,或 CUDA 检测过程本身异常,也会回退到 CPU,避免继续硬走 GPU
- 这样可减少后端因老显卡不兼容而崩溃,前端只显示 `Broken Connection / Connection to the server was lost` 的情况
- 是否能使用 GPU、以及最终速度,仍取决于当前机器的 PyTorch / CUDA / 显卡环境
5. 增加 CPU 安全模式
- 当旧显卡或当前环境不适合走 CUDA 时,整合版会进入 CPU 安全模式
- CPU 安全模式下会强制单并发,并把模型缓存收缩为单模型,减少低配机器同时压多个模型导致的崩溃概率
- 状态页会显示当前是否处于 CPU 安全模式,便于判断当前运行策略
6. 修复低配机器打开网页时就把多个模型全部加载的问题
- 之前页面打开后会自动读取三套模型支持信息
- 对低内存机器来说,这等于启动后立刻轮流加载 `预设音色 / 语音克隆 / 音色设计`
- 现在在 CPU 安全模式下,页面首次打开时改为按需加载
- 只有手动点击“读取模型支持信息”,或真正进入对应功能执行生成时,才会加载相关模型
7. 修复音色设计在 CPU 回退机器上的稳定性
- `音色设计` 页在 CPU 安全模式下也改成分段稳态生成
- 长文本会按段生成后再拼接,减少一次性长推理导致后端退出、前端只显示 `Broken Connection` 的概率
- 状态提示里会显示“音色设计 CPU 分段稳态模式”,方便确认当前是否命中这条保护逻辑
8. 修复“先设计后克隆”在低配机器上的内存冲突
- 之前这条链路会先后取到 `VoiceDesign` 和 `Base` 两套模型对象
- 在旧显卡回退 CPU、且机器内存偏小的情况下,更容易触发后端直接退出
- 现在流程改成严格串行:
- 先加载 `VoiceDesign` 生成参考音频
- 然后主动清缓存
- 再加载 `Base` 做语音克隆
- 这样可以降低两套模型交替占用内存带来的风险
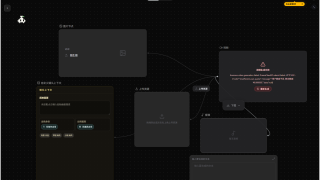
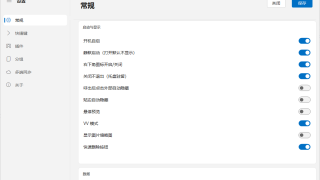
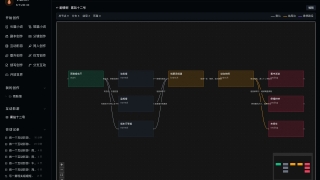
图片预览

注:剧本工坊将在下个版本推出
下载地址

评论抢沙发