升级日志
本次 IndexTTS 升级,重点优化了专家模式下的多线路调度、批量逐句生成、共享主模型策略、长文自动降级机制,以及云端显卡资源利用率。
这次优化的核心目标很明确:让大显存显卡和云端算力不再空闲浪费,在保证稳定性的前提下,尽量提升剧本工坊批量生成的真实吞吐。
它不是简单地把线程数拉高,也不是盲目追求更高的显卡占用率,而是根据文本长度、句子复杂度、显存余量和实际生成表现,动态判断当前批次到底适不适合多路提交,最终追求的是整批任务更快、更稳、更少失败。
为什么会做这次升级
早期刚把应用搬迁到云上的时候,我就明显感受到了云端算力电脑和家庭电脑的不同。
在家用电脑上,生成音频时显卡利用率经常能跑到 95% 左右;但应用搬到云上之后,我发现同样的生成任务,很多时候显卡利用率只有 30% 多。也就是说,模型虽然跑起来了,但 GPU 算力并没有被真正吃满。
这也是我最近一直在重点解决的问题:尽量提高云端显卡的 GPU 利用率,不浪费算力。闭关这么久,总算做出了一些比较满意的成果。
为了让大家更直观地看到差别,这次我也分别做了家庭电脑和云端环境的实测说明。
对于家庭电脑:多线路终于能把大显存显卡用起来
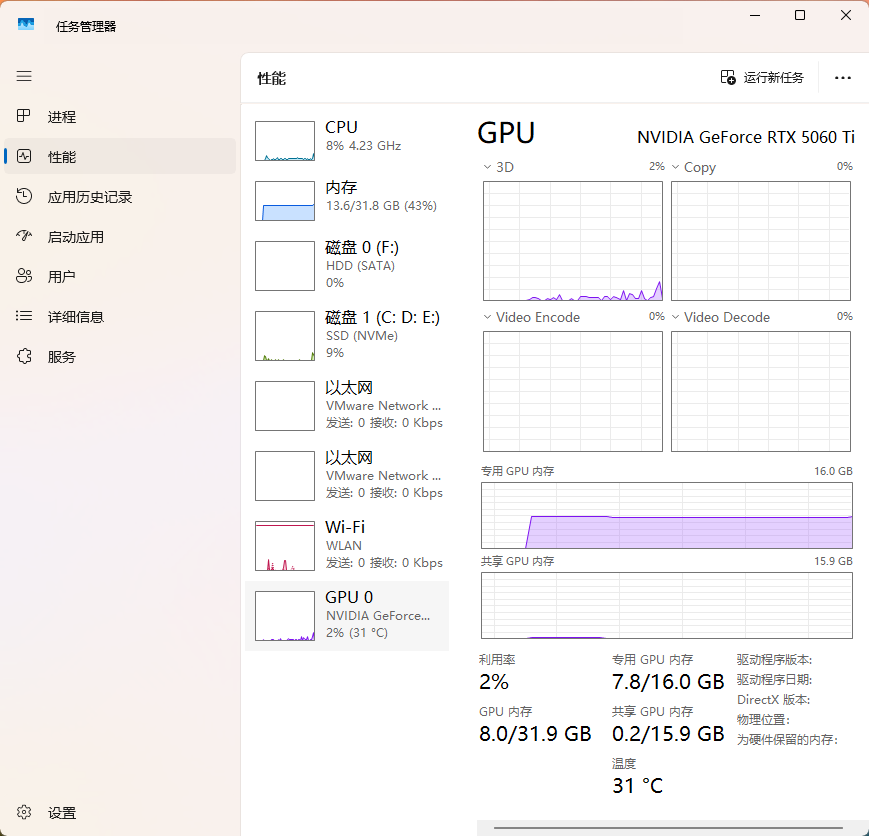
1. 旧版本的显卡占用情况
这是旧版本在生成音频时的显卡占用情况。对于 8G 显卡来说,这样的占用基本够用了;但对于 16G 甚至更高显存的显卡来说,其实浪费了不少 GPU 资源。也正因为这个问题,我才开始策划这次多线路升级。
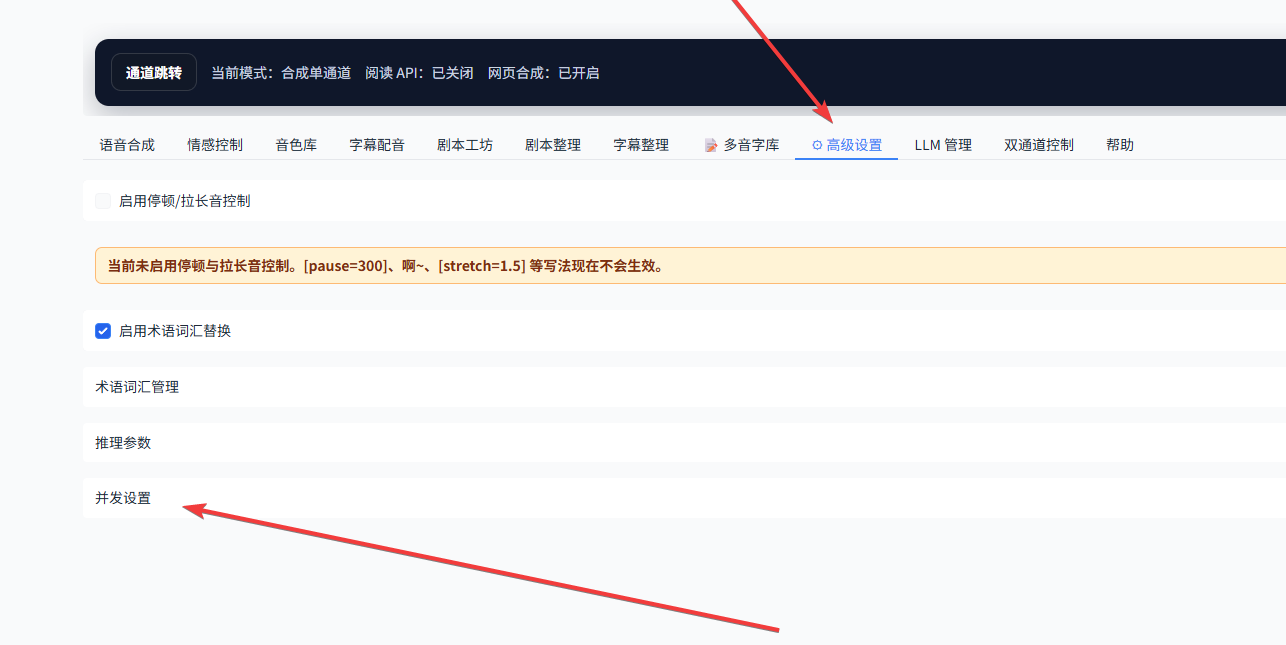
2. 家用多线路设置方法
家用多线路需要在“高级设置”中进行配置。找到自定义设置后,按照下图参数填写,保存并应用并发设置,最后记得重启应用。
如果你是云上环境,重启电脑后也可以直接享受到多线路解锁剩余算力的效果。
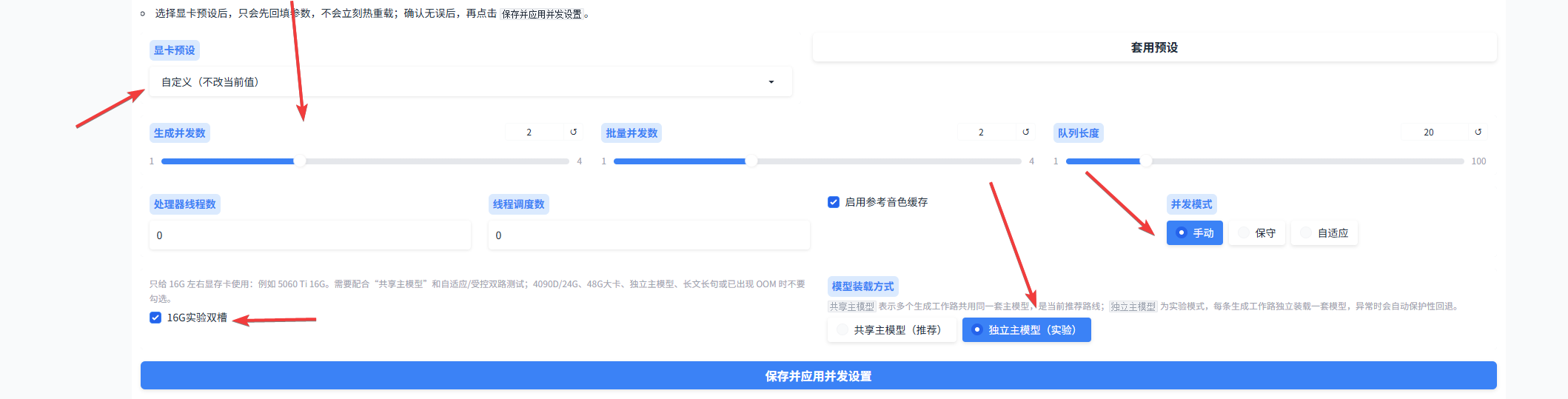
这里需要特别说明一点:多线路对短文本、短句批量的加速效果最明显,但对长文本并不一定能显著加速。
原因并不是多线路无效,而是长文本在生成时会进入更长时间的 GPT 解码阶段,单句任务本身就会持续占用更多显存和计算资源。如果强行让多路长句同时并发,容易出现以下问题:
- 多个长句同时进入解码阶段,彼此争抢显存和算力。
- 表面上 GPU 占用率更高,但单句速度反而变慢。
- 显存波动更大,更容易触发 CUDA 或 allocator 相关错误。
- 最终整批任务的总耗时未必更短,甚至可能更慢。
所以,多线路的价值主要体现在短句批量场景,而不是让所有长文本都强行并发。
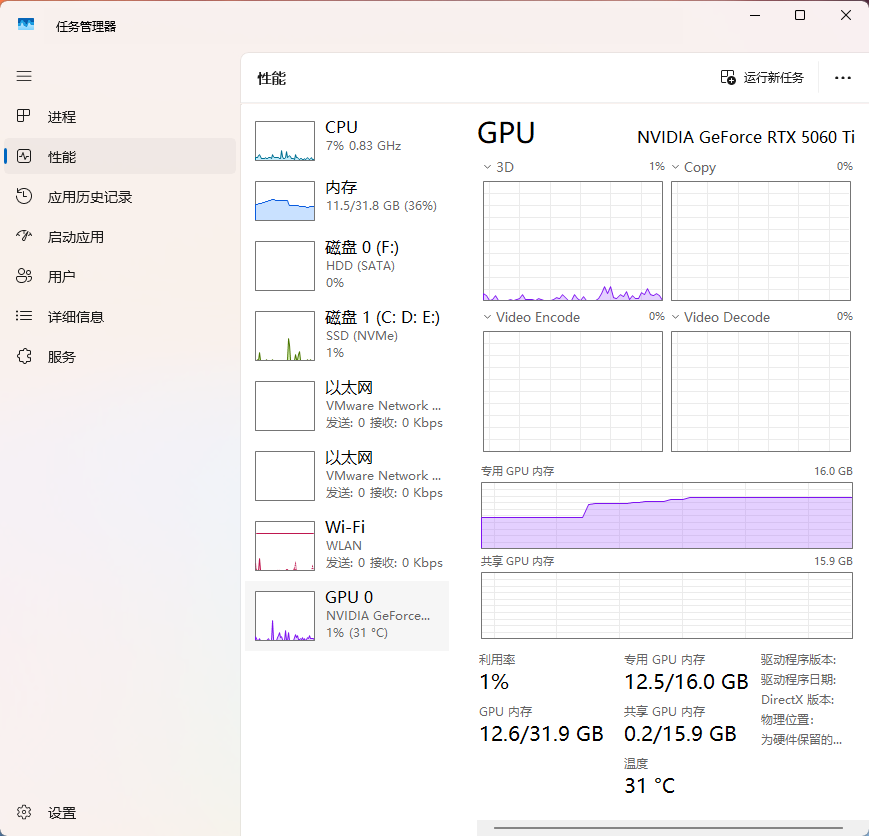
3. 家用多线路显卡占用对比
未工作时:
工作中:
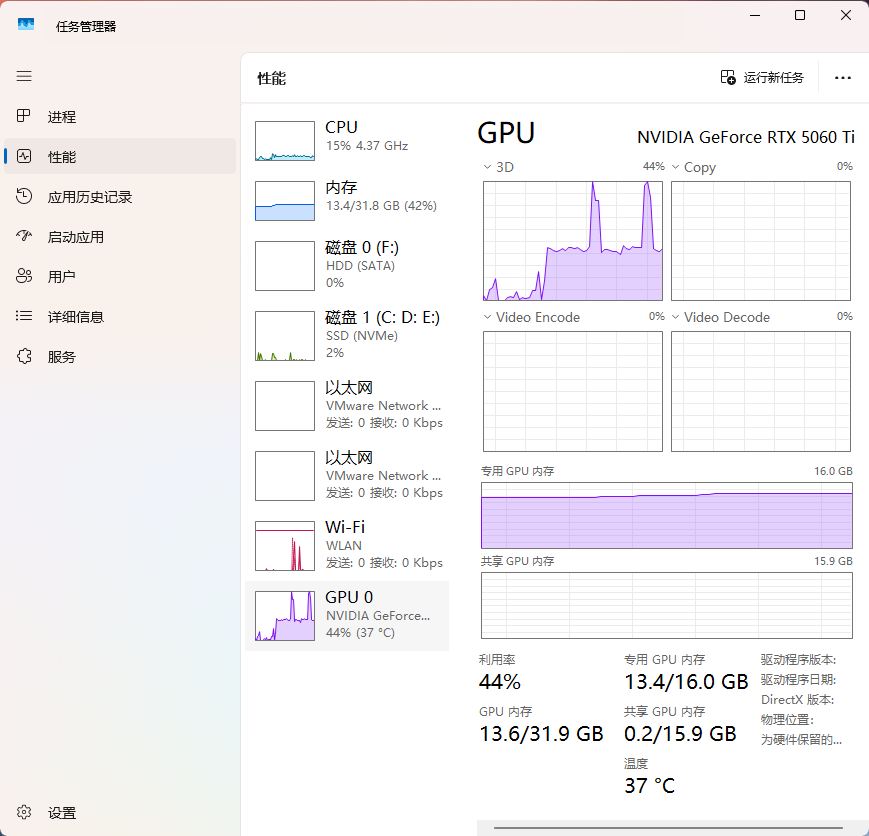
如果你觉得显卡仍然比较游刃有余,可以继续往上调参数再压榨一点性能。不过我自己测试过,3W/3P 的独立线路在某些情况下会直接爆显存,所以更建议优先尝试 3W/3P 共享线路这一类更稳的方案。
对于云端:新版终于把大显存 GPU 利用起来了
云端旧版本占用情况
旧版本在未进行音频任务生成、仅加载模型的状态下,占用如下:
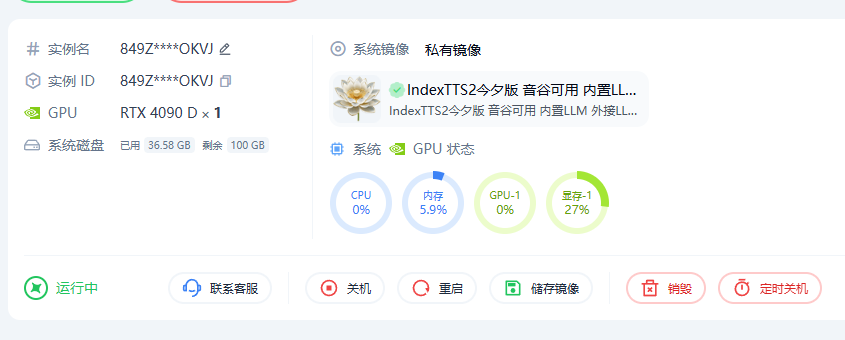
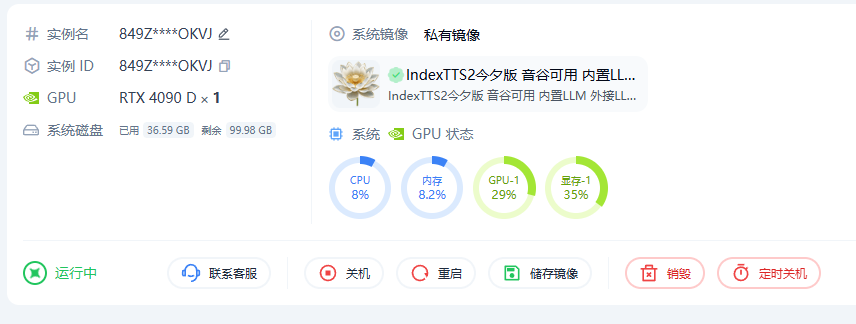
旧版本在工作中的 GPU 利用率如下。可以看到,实际只使用了大约 35% 的 GPU 资源,这也是我决定推出多线路版本的直接原因。
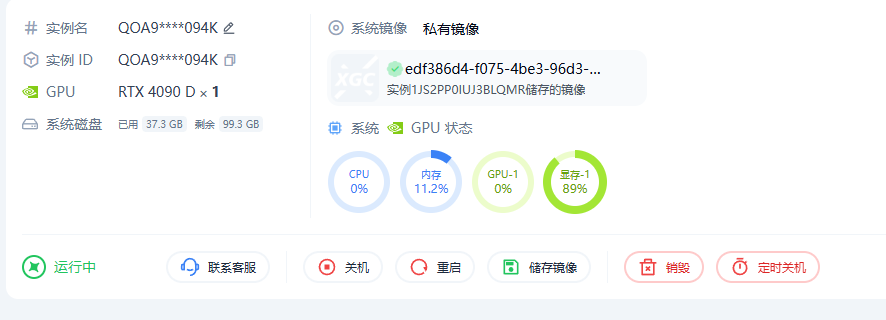
新版本占用情况
新版上线后,GPU 利用率已经可以明显提高,实测可达到 89% 左右:
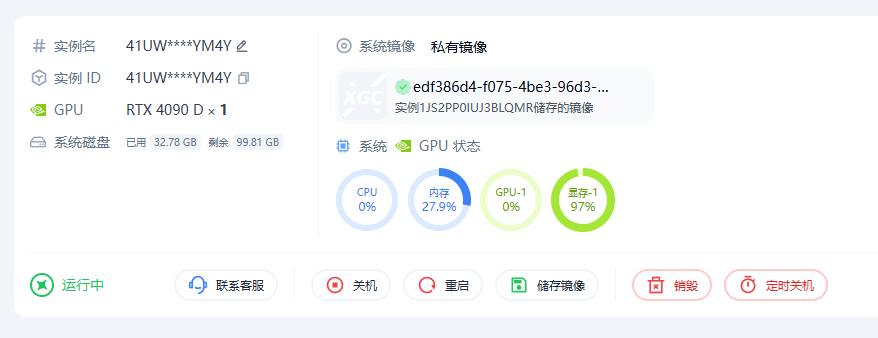
如果继续调整参数,理论上还可以进一步逼近 97%,但我并不推荐这么做。因为我反复测试过,在 4W/4P 这样的配置下,即使是 24G 显卡,也有较高概率在工作中出现报错,也就是大家常说的爆显存。
所以,对于 RTX 4090 D 24G,当前更推荐的方案是:
- 3W/4P + 独立主模型 + 手动:适合单次测速、追求极限速度。
- 3W/4P + 共享主模型 + 手动:更适合长期稳定运行。
如果是 48G 这类更高显存显卡,才更适合进一步往上拉满。
新版并发设置说明
这次我们在新版本设置中加入了并发设置,大家可以根据自己的显卡情况进行调整,推荐如下:
- RTX 4090 D 24G 长文批量:推荐 3W/4P + 共享主模型 + 手动。
- RTX 4090 D 24G 单次测速:可以尝试 3W/4P + 独立主模型 + 手动,但不建议作为默认长期配置。
- 16G 显卡日常使用:推荐自适应,或 2W/2P + 共享主模型。
- 16G 显卡短句批量冲速度:可尝试 2W/4P + 共享主模型。
- 长文长剧本:不要盲目追求实际 2 路并发,最终总耗时更重要。
先解释两个常见参数:W 和 P 是什么
- W 表示生成工作路数量,也就是后台准备了几条生成工作路。
- P 表示批量提交通道数量,也就是批量任务向后台提交任务的通道数量。
- 例如 3W/4P,表示 3 条生成工作路、4 个批量提交通道。
RTX 4090 D 24G 长文实测数据
在 RTX 4090 D 24G 上,我们使用一组 95 句长文剧本进行了实测,运行时识别显存约为 23.5G。
以防大家误会95句文本数据很小 附上测试文本 21KB 7300多字符。1500换算就是25分钟.测试都测试了好久。
https://pan.baidu.com/s/1avWaUeVBkZgMF6EOmtd2jw?pwd=rm3v 提取码: rm3v
| 设置 | 耗时 | 说明 |
| 3W/4P + 独立主模型 + 手动 | 1480.87 秒 | 本轮单次最快,但属于实验模式 |
| 3W/4P + 共享主模型 + 手动,单次最好 | 1488.18 秒 | 和最快结果只差 7.31 秒 |
| 3W/4P + 共享主模型 + 手动,两次平均 | 1497.29 秒 | 更适合作为稳定推荐 |
| 2W/4P + 独立主模型 + 手动 | 1506.79 秒 | 和共享主模型结果接近 |
| 旧版本单路基线 | 2098 秒 | 旧线路参考值 |
从这组数据看,当前较好的 4090 D 24G 长文设置,相比旧版本单路基线,可以节省大约 600 秒,整体提升约 28% 到 29%。
其中,3W/4P + 独立主模型 + 手动是本轮单次最快结果,耗时 1480.87 秒。相比旧版本 2098 秒,快了 617.13 秒,约提升 29.42%。
不过需要强调的是,独立主模型属于实验模式。它需要更多显存,也更容易在多 worker 装载时遇到 CUDA、显存不足或 PyTorch allocator 相关问题。
因此,如果是云端长期稳定使用,更推荐 3W/4P + 共享主模型 + 手动。
共享主模型两次实测分别为 1506.40 秒和 1488.18 秒,平均 1497.29 秒。相比旧版本 2098 秒,平均快了 600.71 秒,约提升 28.63%。
为什么显示“可并发 2 路”,但实际只跑了 1 路
这里有一个大家很容易误解的点,需要单独说明。
这组 95 句长文测试虽然设置了 3W/4P,并且状态里显示“真实可用并发路数为 2”,但实际并没有真正并发到 2 路。
原因是这批文本里长句和超长句占比很高。如果强行让 2 路同时进入 GPT 解码阶段,就会产生明显的资源竞争:
- 两路同时抢显存。
- 两路同时抢解码算力。
- 表面上占用率变高,但实际总耗时未必更短。
- 失败风险和显存波动反而更大。
所以新版调度器并不是只要能开 2 路就一定硬开 2 路,而是优先判断哪种方式能让整批任务总耗时更短、整体更稳定。
对于这类长文批次,系统会主动按单槽提交。
这也解释了为什么状态里会出现下面这几项:
- 实际并发到 2 路:否。
- 本次最高实际提交:1 路。
- 真实可用并发路数:2。
这三者并不矛盾。
“真实可用并发路数为 2”,表示从硬件和运行态来看,当前最多允许 2 路;但“本次最高实际提交为 1 路”,表示调度器判断这批文本更适合单路执行。
简单说,不是 3W/4P 没生效,也不是并发是假的,而是系统识别到这批长文不适合硬开 2 路,所以主动选择了更快、更稳的执行方式。
16G 显卡的实际建议
在 16G 显卡上,短句批量场景同样有明显优化。
此前 8 句固定映射短句基准中,共享主模型路线相比旧单路基线,实测可以带来大约 30% 的效率提升。
不过,16G 显卡不建议一上来就强行拉满。自适应策略会更保守,通常会先落到 2W/2P + 共享主模型,再根据空闲显存和历史表现决定是否升到 2W/4P。
所以对大多数 16G 用户来说:
- 日常使用:优先自适应。
- 希望稳定:2W/2P + 共享主模型。
- 短句批量冲速度:尝试 2W/4P + 共享主模型。
本次升级还修复和完善了哪些内容
除了核心调度和并发策略外,本次升级还修复和完善了多个剧本工坊相关问题,包括:
- 长任务按钮锁定。
- 批量逐句生成防重复点击。
- 拼接导出进度提示。
- 音频播放器刷新。
- 剧本切换后的旧状态清理。
- 未绑定音色时的生成提示。
- 坏行诊断。
- 对齐诊断。
对于用户来说,最直接的变化就是:
- 长剧本批量生成更稳。
- 状态提示更清楚。
- 设置是否生效更容易判断。
- 导出和试听流程也更不容易卡死。
最后的结论
如果你使用的是云端显卡,这次升级的意义会更明显。
过去旧线路在大显存显卡上,往往只能吃掉一部分资源,显存和算力都存在浪费。新版通过共享主模型、批量调度和长文自动判断,不再单纯追求高占用,而是追求真实可用的吞吐提升。
可以简单总结成一句话:
- 短句批量更适合吃多线路和批量解码收益。
- 长文长句更适合让调度器判断是否回到单槽提交。
真正应该关注的,不是界面上是否一直显示 2 路同时跑,而是整批任务最终是否更快、更稳、更少失败。
当前推荐结论:
- 4090 D 24G 长文稳定使用:优先选择 3W/4P + 共享主模型 + 手动。
- 4090 D 24G 单次测速:可以尝试 3W/4P + 独立主模型 + 手动。
- 普通用户和云端长期运行:建议优先使用共享主模型。
云端镜像体验地址
https://www.xiangongyun.com/image/detail/dd21c91f-e2eb-4068-b6c7-d426b40a68e7




评论抢沙发