简介说明
VoxCPM2:基于连续表征的多语言语音合成、创意音色设计与高保真声音克隆
VoxCPM 是一个无离散音频分词器(Tokenizer-Free)的语音合成系统,通过端到端的扩散自回归架构直接生成连续语音表征,绕过对音频的离散编码步骤,实现高度自然且富有表现力的语音合成。
VoxCPM2 是最新的版本,基于 MiniCPM-4 基座构建,总计 20亿参数,在超过 200万小时的多语种音频数据上训练,支持 30种全球语言+9种中文方言、音色设计、可控声音克隆,原生输出 48kHz 高质量音频。
核心特性
30种语言语音合成,直接输入原始文本即可合成(支持语言详见下文),无需额外语言标签
音色设计,用自然语言描述(性别、年龄、音色、情绪、语速……)凭空创建全新音色,无需参考音频
可控声音克隆,从参考音频片段克隆任意声音,可叠加风格指令控制情绪、语速和表现力,同时保持原始音色
极致克隆,提供参考音频及其文本内容,模型接着参考音频进行无缝续写,从而精准还原声音细节特征(与 VoxCPM1.5 一致)
48kHz 高质量音频,输入 16kHz 参考音频,通过 AudioVAE V2 的非对称编解码设计直接输出 48kHz 高质量音频,内置超分能力
语境感知合成,根据文本内容自动推断合适的韵律和表现力
实时流式合成,在 NVIDIA RTX 4090 上 RTF 低至 ~0.3,通过 Nano-vLLM 或 vLLM-Omni(官方 vLLM 全模态服务,原生支持 VoxCPM2,提供 PagedAttention 与 OpenAI 兼容 API)加速后可达 ~0.13
完全开源,商用就绪,权重和代码基于 Apache-2.0 协议发布,免费商用
支持的语言(30种)
阿拉伯语、缅甸语、中文、丹麦语、荷兰语、英语、芬兰语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、高棉语、韩语、老挝语、马来语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、斯瓦希里语、瑞典语、菲律宾语、泰语、土耳其语、越南语
中国方言:四川话、粤语、吴语、东北话、河南话、陕西话、山东话、天津话、闽南话
最新动态
[2026.04] 发布 VoxCPM2 — 20亿参数,30种语言,音色设计与可控声音克隆,48kHz 音频输出!模型权重 | 使用文档 | 在线体验 | 官网体验 (适用国内访问)
[2025.12] 开源 VoxCPM1.5 模型权重,支持 SFT 和 LoRA 微调。
[2025.09] 发布 VoxCPM 技术报告。
[2025.09] 开源 VoxCPM-0.5B 模型权重
快速开始
安装
pip install voxcpm
环境要求: Python ≥ 3.10 (<3.13),PyTorch ≥ 2.5.0,CUDA ≥ 12.0。详见 快速开始文档。
Python API
文本转语音
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained(
"openbmb/VoxCPM2",
load_denoiser=False,
)
wav = model.generate(
text="VoxCPM2 是目前推荐使用的多语言语音合成版本。",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)
print("已保存: demo.wav")
国内网络从 ModelScope 下载模型到本地:
pip install modelscope
from modelscope import snapshot_download
snapshot_download("OpenBMB/VoxCPM2", local_dir='./pretrained_models/VoxCPM2')
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained('./pretrained_models/VoxCPM2', load_denoiser=False)
wav = model.generate(
text="VoxCPM2 是目前推荐使用的多语言语音合成版本。",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)
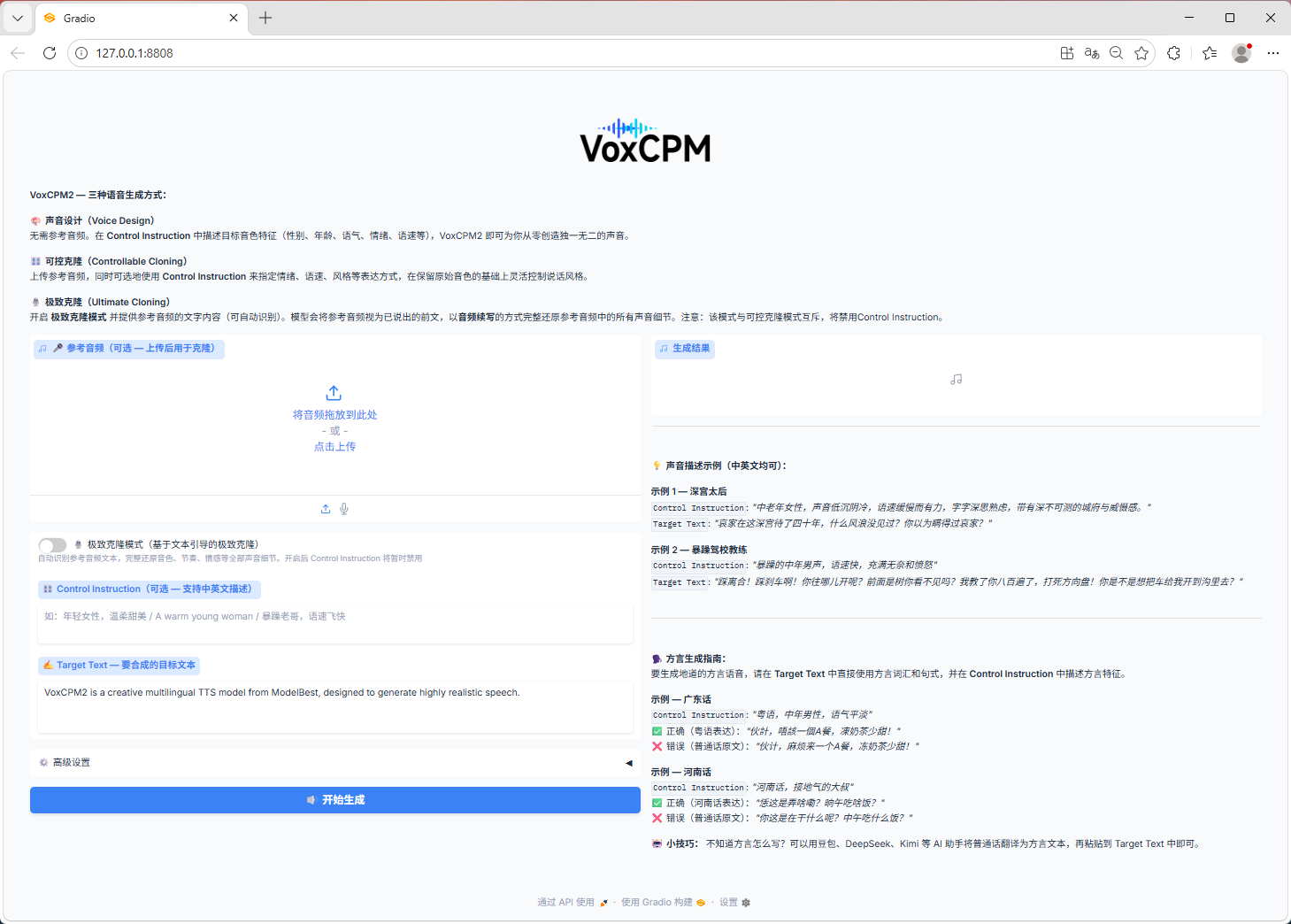
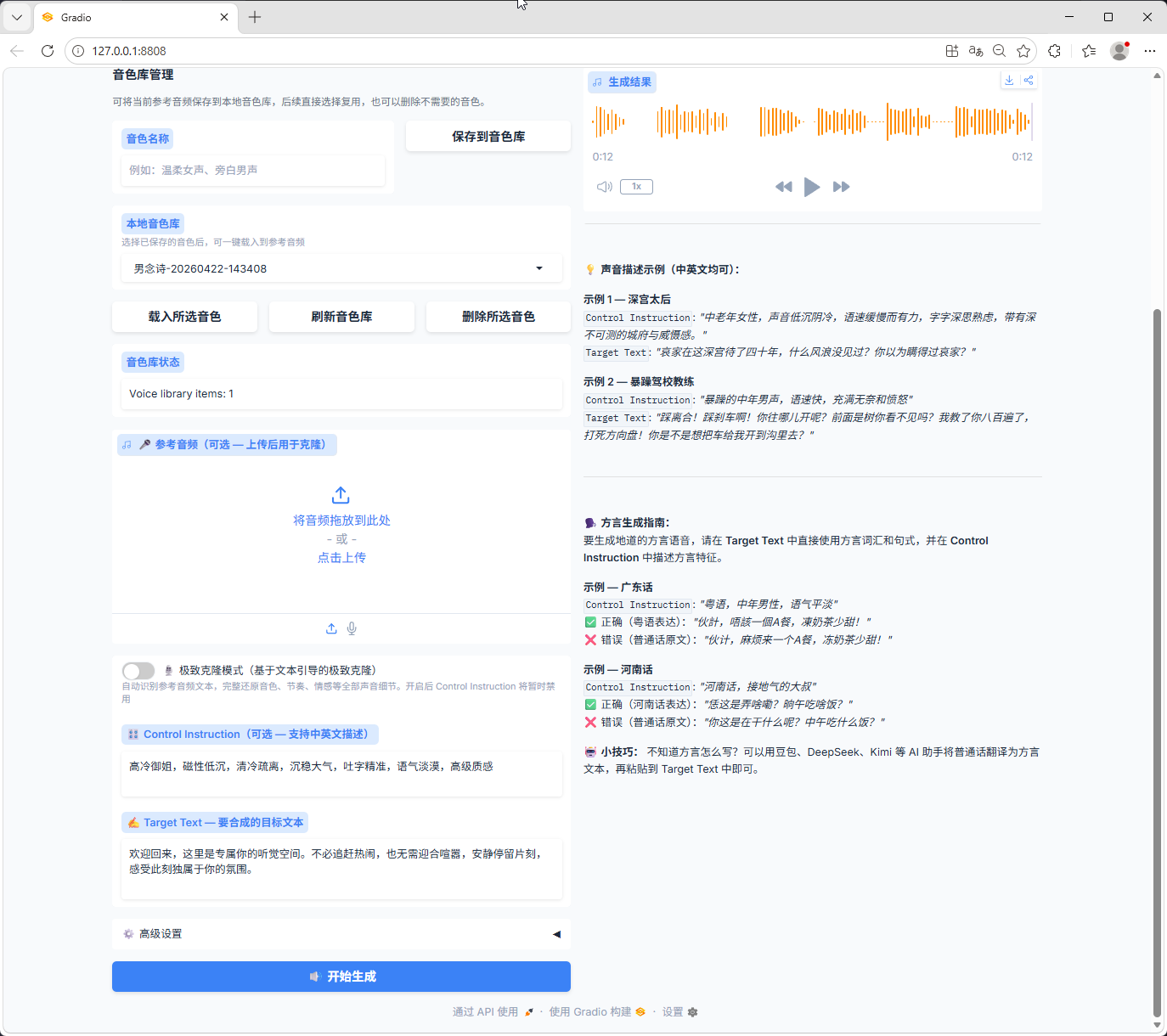
音色设计
wav = model.generate(
text="(年轻女性,声音温柔甜美)你好,欢迎使用VoxCPM2!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("voice_design.wav", wav, model.tts_model.sample_rate)
可控声音克隆
wav = model.generate(
text="这是VoxCPM2生成的克隆语音。",
reference_wav_path="path/to/voice.wav",
)
sf.write("clone.wav", wav, model.tts_model.sample_rate)
wav = model.generate(
text="(稍快一点,欢快的语气)这是带风格控制的克隆语音。",
reference_wav_path="path/to/voice.wav",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("controllable_clone.wav", wav, model.tts_model.sample_rate)
极致克隆
wav = model.generate(
text="这是使用VoxCPM2的极致克隆演示。",
prompt_wav_path="path/to/voice.wav",
prompt_text="参考音频的文本转录。",
reference_wav_path="path/to/voice.wav",
)
sf.write("hifi_clone.wav", wav, model.tts_model.sample_rate)
命令行使用
音色设计(无需参考音频) voxcpm design \ --text "VoxCPM2带来全新语音合成体验。" \ --output out.wav 可控声音克隆(带风格控制) voxcpm design \ --text "VoxCPM2带来全新语音合成体验。" \ --control "年轻女声,温暖温柔,略带微笑" \ --output out.wav 声音克隆(参考音频) voxcpm clone \ --text "这是一个声音克隆的演示。" \ --reference-audio path/to/voice.wav \ --output out.wav 极致克隆(提示音频 + 转录文本) voxcpm clone \ --text "这是一个声音克隆的演示。" \ --prompt-audio path/to/voice.wav \ --prompt-text "参考音频转录文本" \ --reference-audio path/to/voice.wav \ --output out.wav 批量处理 voxcpm batch --input examples/input.txt --output-dir outs 帮助 voxcpm --help
Web Demo
python app.py --port 8808
生产部署
Nano-vLLM
pip install nano-vllm-voxcpm
from nanovllm_voxcpm import VoxCPM
import numpy as np, soundfile as sf
server = VoxCPM.from_pretrained(model="/path/to/VoxCPM", devices=[0])
chunks = list(server.generate(target_text="你好,我来自VoxCPM!"))
sf.write("out.wav", np.concatenate(chunks), 48000)
server.stop()
vLLM-Omni
安装
uv pip install vllm==0.19.0 --torch-backend=auto
git clone https://github.com/vllm-project/vllm-omni.git && cd vllm-omni
uv pip install -e .
启动服务
vllm serve openbmb/VoxCPM2 --omni --port 8000
调用
curl http://localhost:8000/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{"model":"openbmb/VoxCPM2","input":"你好,欢迎使用 VoxCPM2 on vLLM-Omni!","voice":"default"}' \
--output out.wav
模型与版本
VoxCPM2 为最新版本,20亿参数,48kHz采样率,支持30种语言,具备音色设计与可控克隆能力,RTX 4090下RTF~0.30,Nano-VLLM加速后~0.13,显存占用~8GB;VoxCPM1.5为稳定版,0.6B参数,44.1kHz采样率,支持中英双语;VoxCPM-0.5B为旧版,0.5B参数,16kHz采样率,支持中英双语。三者均支持SFT与LoRA微调。
VoxCPM2 采用连续音频表征、扩散自回归范式,模型在 AudioVAE 的连续隐空间中通过四阶段处理:LocEnc → TSLM → RALM → LocDiT,实现丰富的表现力语音合成和 48kHz 原生音频输出。
性能评测
VoxCPM2 在公开的零样本和可控 TTS 基准测试中取得了 SOTA 或可比的结果,涵盖 Seed-TTS-eval、CV3-eval、MiniMax-Multilingual-Test 等多项评测,并完成内部30语种可懂度 benchmark 测试。
微调
VoxCPM 支持全参数微调(SFT)和 LoRA 微调,仅需 5-10分钟的音频数据,即可适配特定说话人、语言或领域。
LoRA 微调
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v2/voxcpm_finetune_lora.yaml
全参数微调
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v2/voxcpm_finetune_all.yaml
WebUI 训练与推理
python lora_ft_webui.py
生态与社区
项目包含 Nano-vLLM、vLLM-Omni、VoxCPM.cpp、VoxCPM-ONNX、VoxCPMANE、voxcpm_rs 以及多款 ComfyUI 工作流与 TTS WebUI 扩展,社区项目非 OpenBMB 官方维护,欢迎贡献提交。
风险与局限性
滥用风险:VoxCPM 的声音克隆能力可生成高度逼真的合成语音。严禁将 VoxCPM 用于冒充他人、欺诈或虚假信息传播,建议对所有 AI 生成内容进行明确标注。
可控生成稳定性:音色设计和可控克隆结果可能存在差异,建议多次生成选取最优效果。
语言覆盖:当前支持30种官方语言,其余语言可通过测试或微调适配。
模型基于 Apache-2.0 协议开源,生产部署建议完成场景测试与安全评估。
引用
@article{voxcpm2_2026,
title = {VoxCPM2: Tokenizer-Free TTS for Multilingual Speech Generation, Creative Voice Design, and True-to-Life Cloning},
author = {VoxCPM Team},
journal = {GitHub},
year = {2026},
}
@article{voxcpm2025,
title = {VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation
and True-to-Life Voice Cloning},
author = {Zhou, Yixuan and Zeng, Guoyang and Liu, Xin and Li, Xiang and
Yu, Renjie and Wang, Ziyang and Ye, Runchuan and Sun, Weiyue and
Gui, Jiancheng and Li, Kehan and Wu, Zhiyong and Liu, Zhiyuan},
journal = {arXiv preprint arXiv:2509.24650},
year = {2025},
}
许可证
VoxCPM 模型权重和代码基于 Apache-2.0 协议开源。
图片预览
原版
今夕自用版
下载地址




评论抢沙发