简介说明
OmniVoice tts优化版一键包 低配置可用最低支持3G显卡 文本转语音 配音系统 语音克隆 音色设计 无需上传参考音频 可控制停顿 叹息 笑声 附带源码
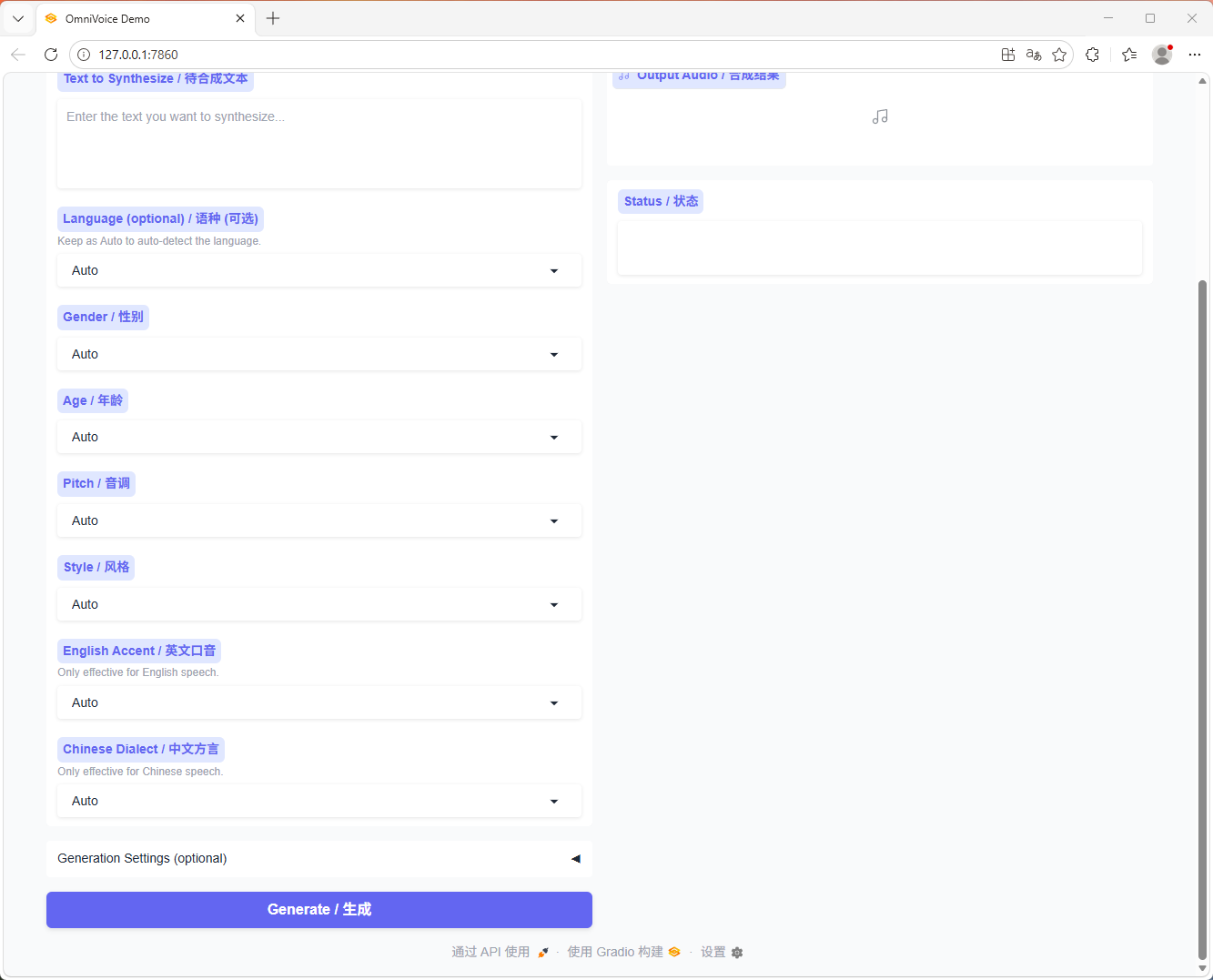
1. 文本转语音
- 支持普通文本直接生成语音
- 支持多语言文本输入
2. 语音克隆
- 上传参考音频即可克隆音色
- 可配合参考文本使用
- 也可省略参考文本,由 Whisper 自动转写参考音频
3. 音色设计
- 无需参考音频
- 可通过文本指令直接设计音色
- 支持性别、年龄、音高、口音/方言、耳语等属性控制
4. 自动音色
- 不提供参考音频和设计指令时,可让模型自动选择音色
5. 细粒度控制
- 支持非语言标签,如 `[laughter]`、`[sigh]`
- 支持中文发音控制
- 支持英文 CMU 音标式发音覆盖
6. 推理参数控制
- 支持步数、语速、固定时长、CFG 等推理参数
- 支持长文本分段推理
7. 命令行工具
- `omnivoice-demo`: 原版 Gradio 演示页
- `omnivoice-infer`: 单条推理
- `omnivoice-infer-batch`: 批量推理
8. Python API
- 支持通过 Python 代码直接调用 `model.generate(...)`
- 适合二次开发、脚本调用、服务封装
项目特点
- 多语言覆盖非常广
- 语音克隆质量高
- 音色设计能力完整
- 推理速度快
- 适合本地部署、API 封装和页面集成
图片预览

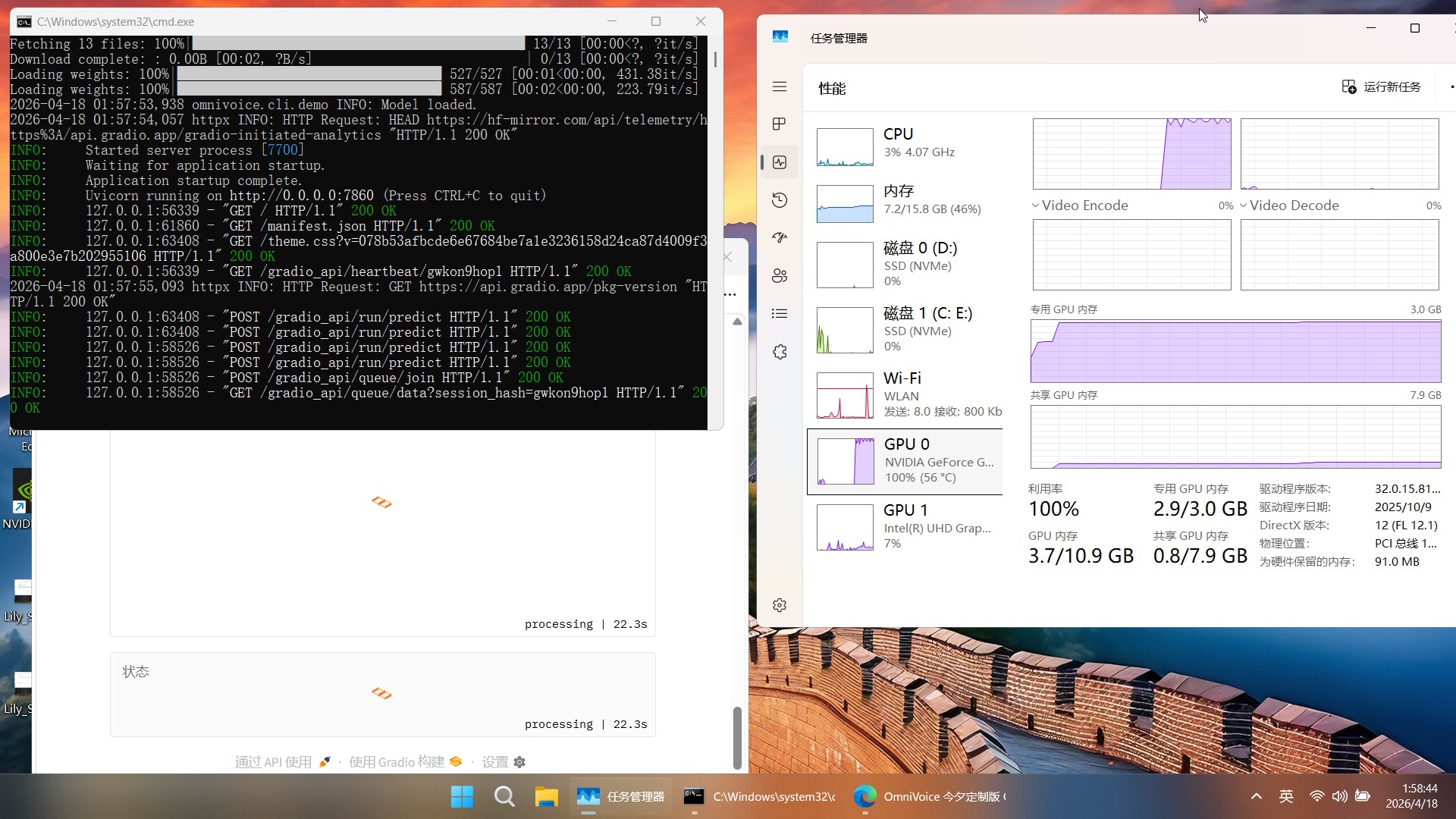
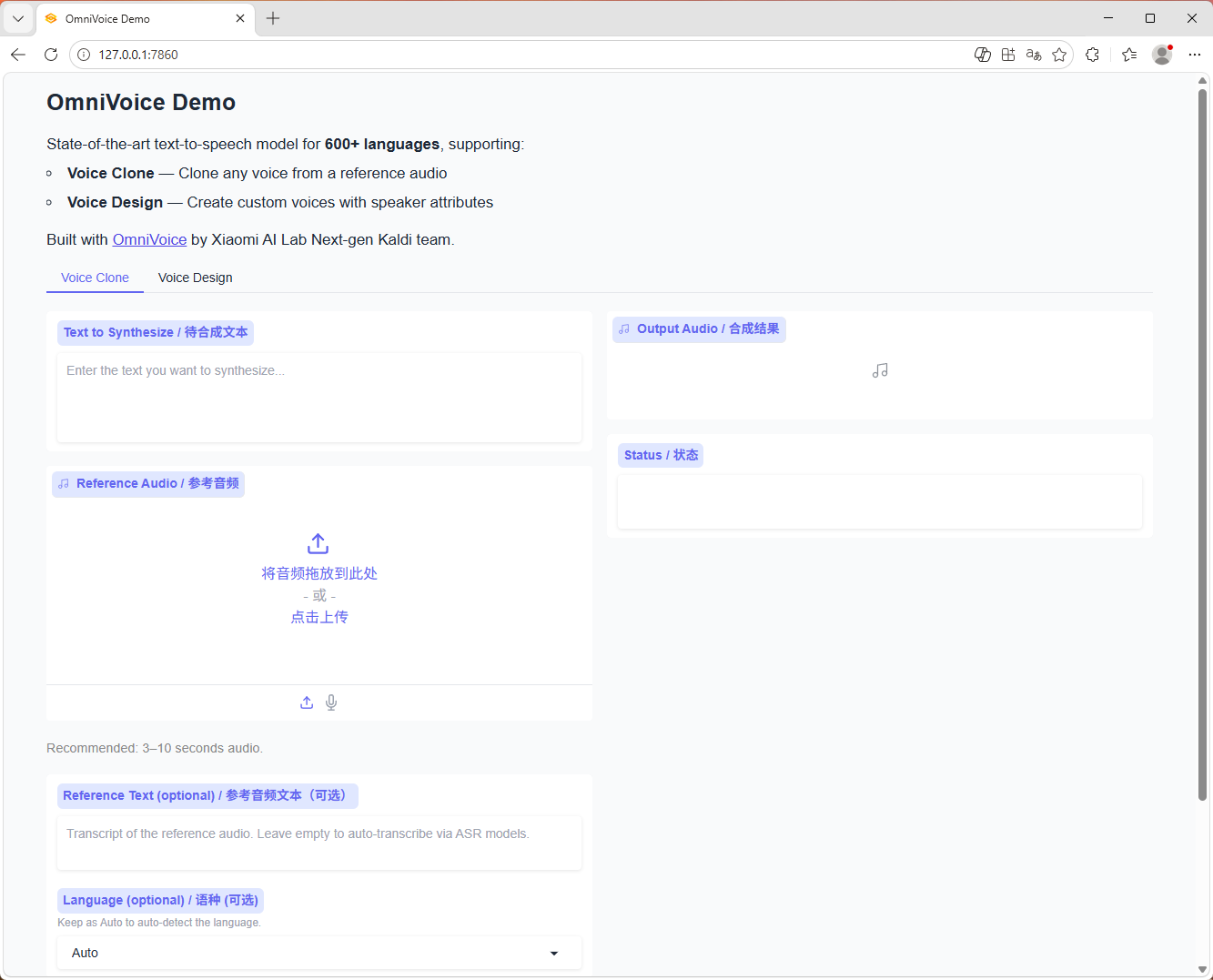
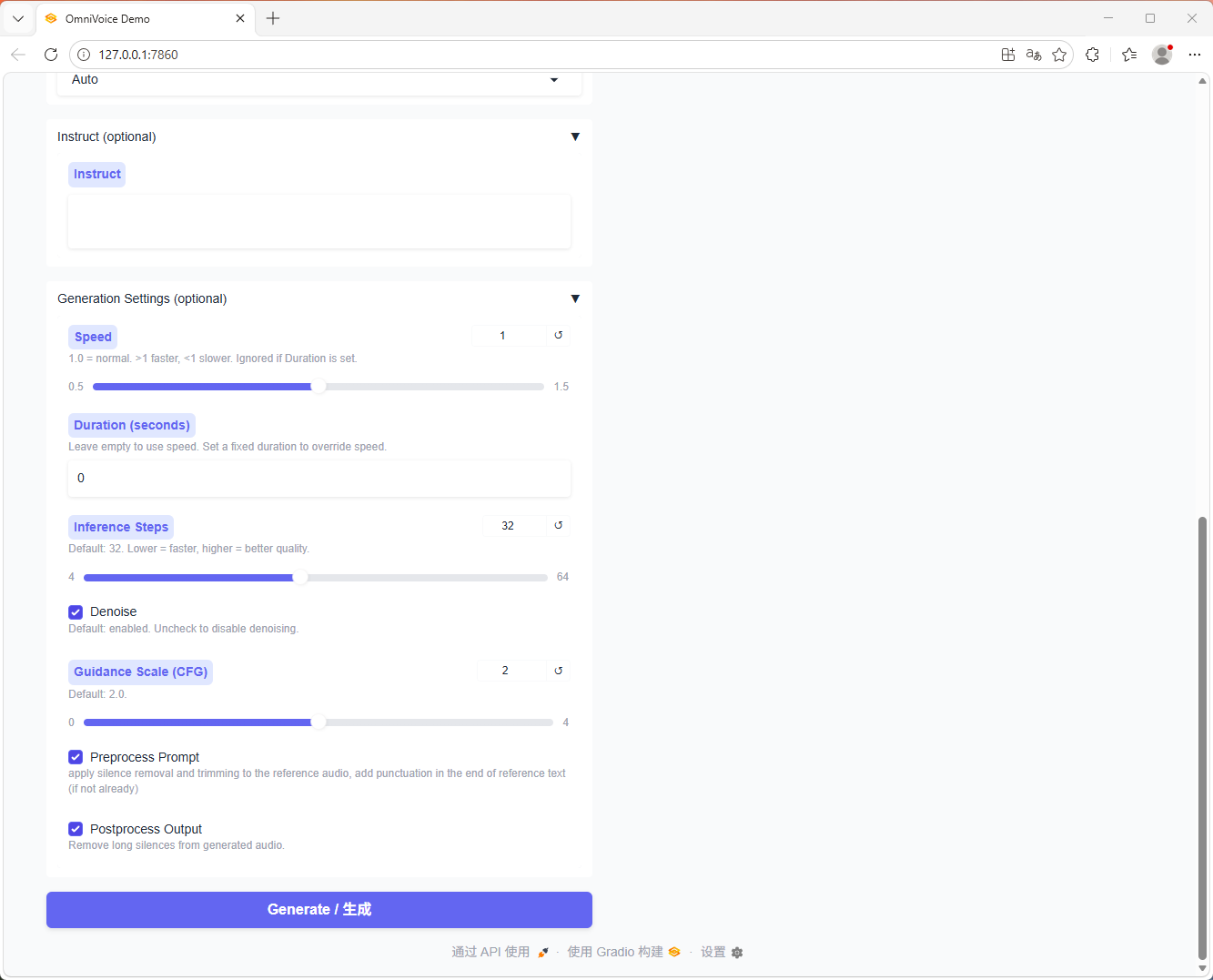
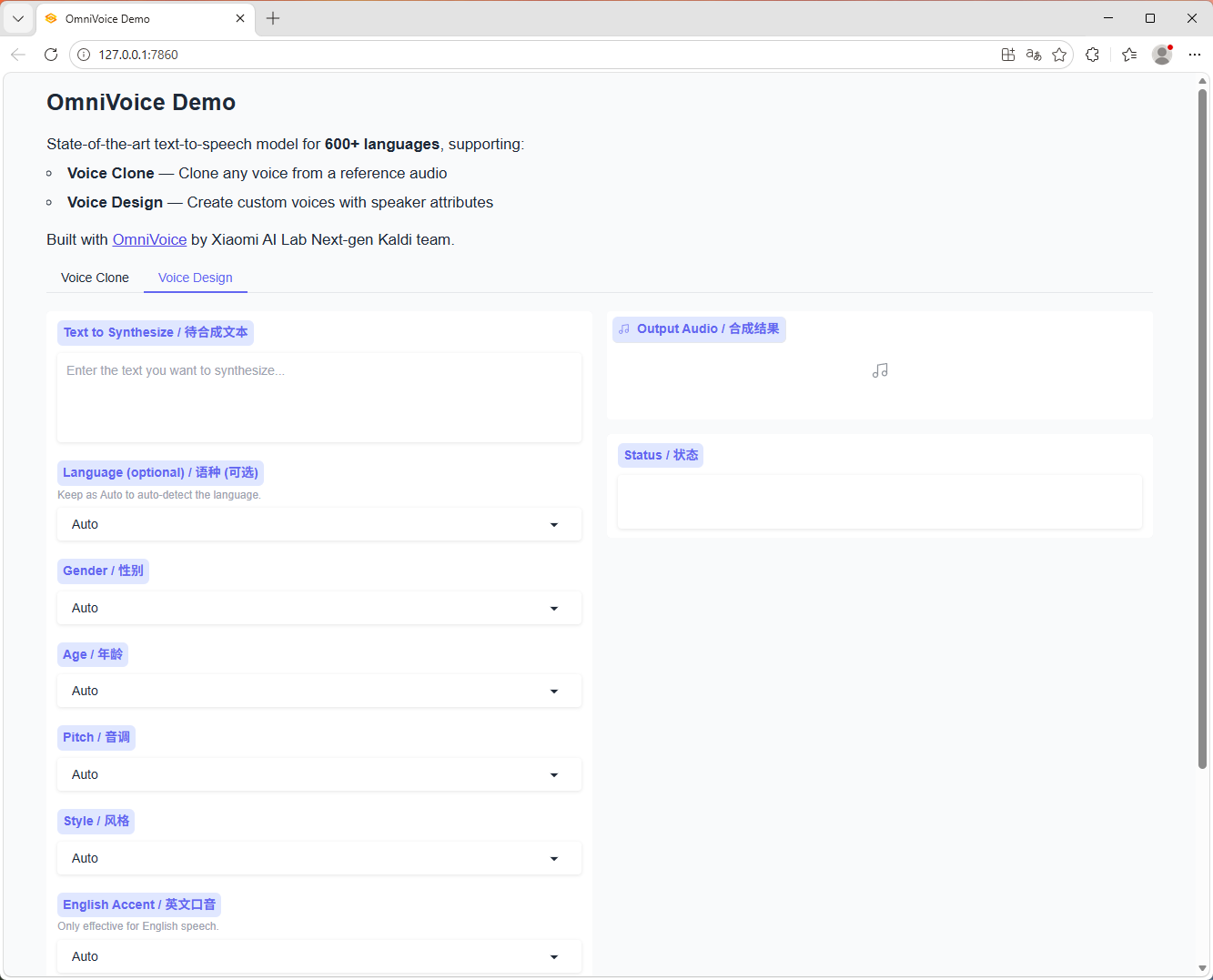
下载地址
https://github.com/k2-fsa/OmniVoice
一键包下载(含源码)
https://pan.baidu.com/s/1R3XOC3fEQUYE3z_K_ibP9Q?pwd=d3ts 提取码: d3ts




评论抢沙发