简介说明
音谷今夕定制版 系统全维度升级 优化后台播放、增强音色管理,提升LLM拆分与角色匹配能力,补全核心功能短板 支持本地大模型接入
核心升级内容
本次升级围绕七大核心方向展开,同步修复优化多项实用功能,补全各类能力短板,具体详情如下:
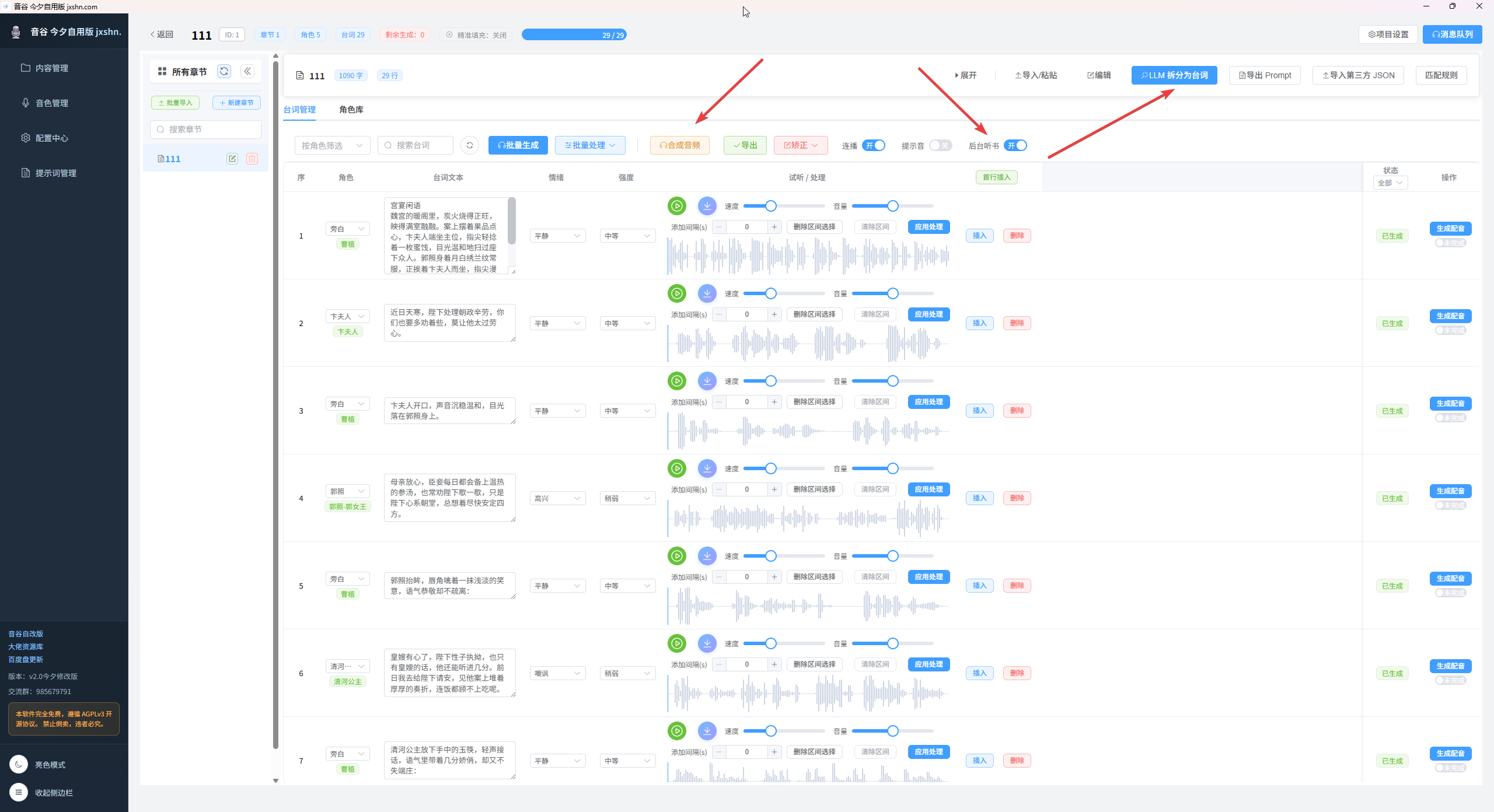
一、后台播放保活与章节音频合成优化
1. 新增“后台听书”开关:在项目配音详情页新增该开关,启用后将执行三项策略——禁用Electron窗口后台节流、主进程启用powerSaveBlocker电源保护、播放器在后台异常暂停时尝试自动续播,保障后台听书连续性。
2. 修复后台最小化自动停播问题:此前因虚拟列表仅渲染当前可见区域,导致后续行波形播放器实例未挂载,顺序播放推进后无法获取下一行播放器句柄而中断;本次修复新增顺序播放兜底逻辑,当WaveCellPro实例不存在时,自动切换到全局audioPlayer继续播放下一条,避免过度依赖虚拟列表已挂载组件,彻底解决后台连续听书部分行停播、长章节顺序播放中段断开的问题。
3. 新增章节音频合成功能:支持将同一章节下已生成完成的台词音频,按line_order顺序自动合成为一条完整音频;本次补全后端章节音频收集与顺序拼接逻辑、前端“合成音频”按钮入口、合成成功结果提示、缺失音频台词统计与告警四大能力,适配章节试听、整章导出前快速检查节奏、多台词音频合并为单条成品等场景;若章节中部分台词未生成音频,系统会明确提示缺失数量,方便用户补生成。
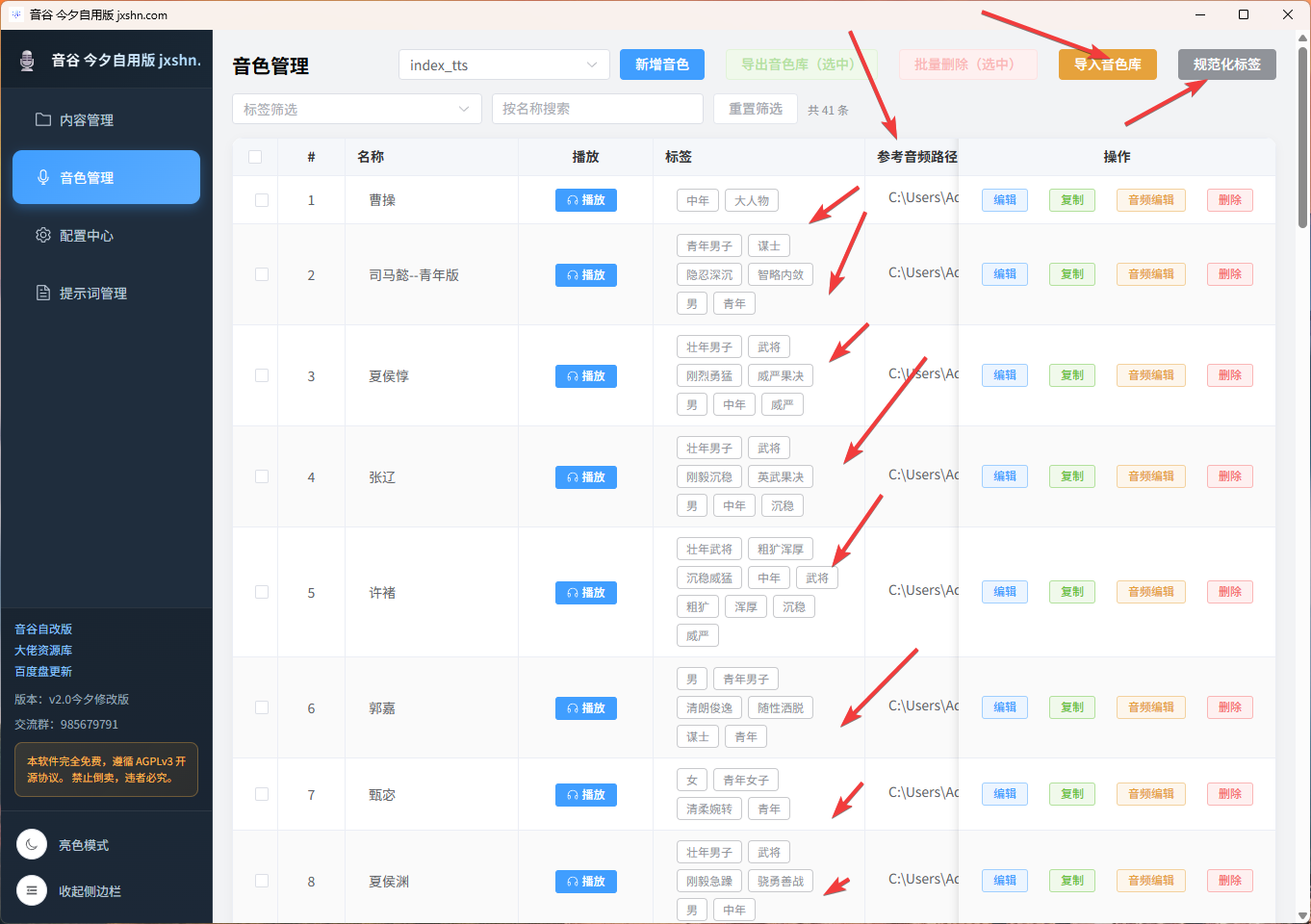
二、音色管理能力升级
1. 标签输入体验增强:在音色管理中,强化“输入一句描述自动拆标签”能力,例如输入“壮年武将,粗犷浑厚,沉稳威猛”,会自动拆分为多个可用于打标的标签,便于后续音色的搜索、分类及智能角色匹配。
2. 新增音色标签规范化工具:新增该工具用于批量给现有音色补标准标签,已补齐后端批量规范化接口、DTO定义、前端按钮入口,以及规则推断、补标签、去重、回写全流程逻辑;可让现有音色数据更整齐,提升自动匹配角色时的命中率,减少“女角色匹配到男音色”“标签混乱导致匹配偏差”的问题。
3. 音色导入能力增强:音色管理页优化批量导入入口,同时优化导入说明文案,新增推荐模板示例、列格式说明,让用户可直接参照填写,减少反复试错成本。
4. 常见办公格式导入扩展:围绕批量导入需求,扩展txt/docx/xls/xlsx等常见办公格式的导入交互与说明设计,适配编号、角色名、人设描述、标签、参考音频路径等结构化音色资料导入,同时支持默认参考路径等便捷策略,提升导入效率。
三、LLM拆分台词能力提升
1. 默认拆分提示词重写:原有提示词在短引号台词误判为旁白、“引号+动作描写+引号”混合句式拆错、说话前后动作归属混乱、角色台词与旁白拆分边界不稳等场景易出错;本次重写默认拆分提示词,重点强化引号内文本优先识别为台词、短句台词不得因过短归入旁白、“说着、笑道、叹道、缓缓道”等小说常见模式识别、引号前后动作/神态/旁白的边界拆分,且旁白统一标注为“平静/中等”,彻底解决各类拆分偏差问题。
2. 情绪与强度解析稳定性提升:此前存在“模型已返回emotion/strength,但页面仍显示缺失”的问题,本次确认并修复两大根因——后端对情绪和强度名称匹配过于严格,非标准同义词会被丢弃;精准填充流程在部分场景下会把空白情绪/强度占位写回;已完成的修复包括增加情绪和强度别名映射、对常见同义词进行标准化处理、精准填充时对空白字段做回退处理;示例别名:悲伤→伤心、恐惧→害怕、愤怒→生气、惊讶→惊喜、强→强烈、失望→伤心、委屈→伤心、沮丧→低落、绝望→低落。
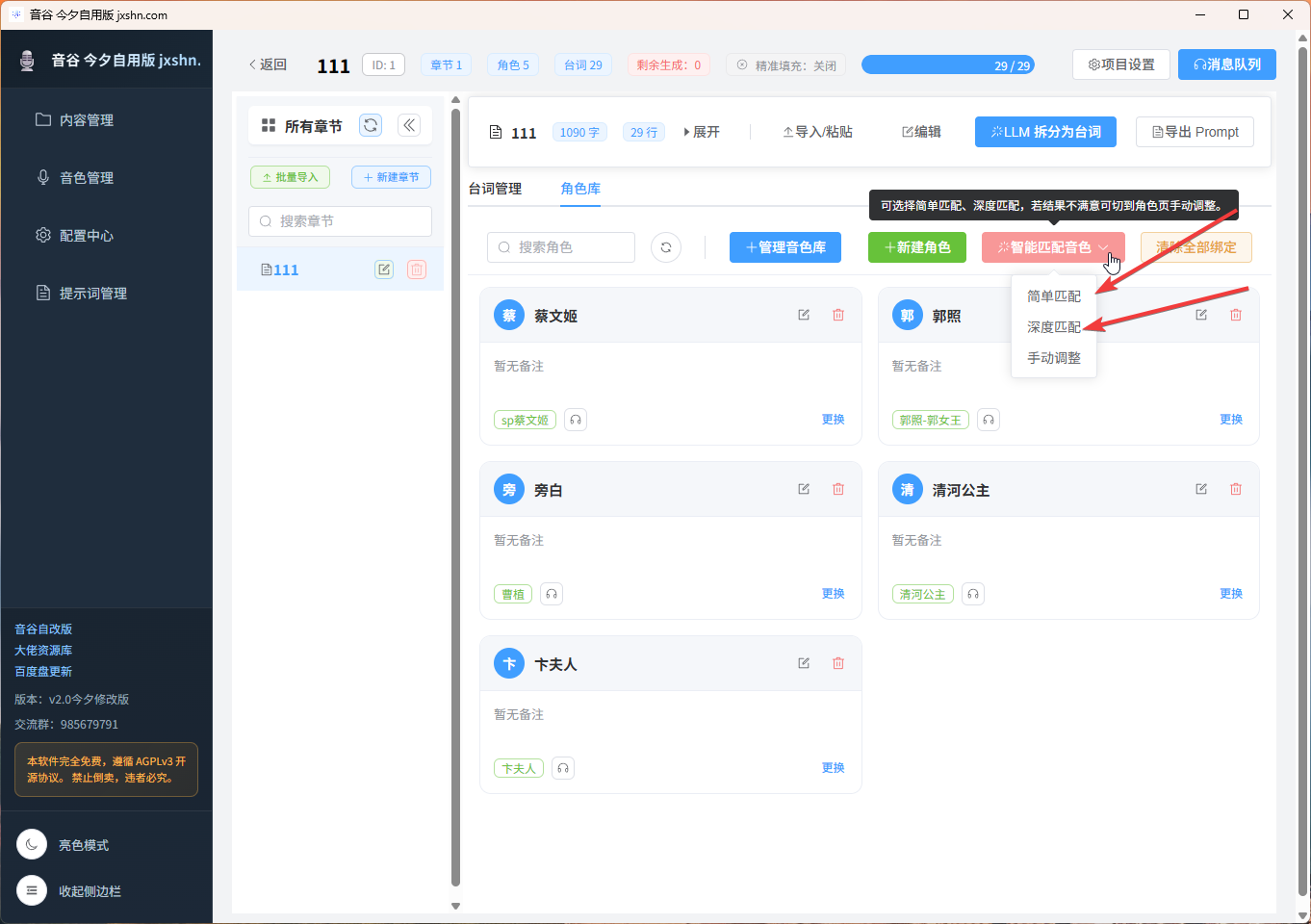
四、智能角色配音匹配升级
1. 两阶段匹配升级:旧逻辑依赖大模型直接猜测配音名,稳定性较差;新逻辑升级为两阶段匹配,先本地提取角色画像和音色画像,再本地做候选打分与排序,随后将候选列表交给LLM做更小范围判断,若LLM返回异常,再回退到本地排序结果,大幅提升匹配稳定性。
2. 新增性别过滤:为减少明显错误匹配,新增硬性性别过滤策略——若角色性别已知,且当前音色库中存在同性候选,则优先排除异性候选;主要解决女角色被绑定到男配音、男角色被绑定到明显女性音色的问题。
3. 前端匹配结果展示增强:智能匹配后,前端会直观提示角色名和匹配到的音色名,方便用户快速检查匹配结果是否合理。
4. 匹配准确性建议:若需更准确的自动匹配,建议先执行音色标签规范化,再执行智能匹配角色,为后续“后处理修正器”落地打下基础。
五、拆分链路升级为“分段拆分、分段落库、实时刷新”,提升拆分结果保真性
优化目标:尽量保留原文完整性、减少角色和旁白误分配、降低情绪/强度缺失比例、降低长段文本拆分错位。
此前问题:LLM拆分流程偏向“整章处理完成后一次性返回结果”,长章节场景下存在用户等待久、前端无法及时确认拆分进度、中途失败难判断已完成内容等问题。
本次升级:将拆分链路升级为实时式处理,后端先按章节内容切分为多个chunk,每个chunk单独调用一次LLM进行拆分,每完成一个chunk立即写入数据库;前端通过WebSocket实时接收当前段数、总段数、已写入条数等进度信息,台词列表和角色列表在拆分过程中分批刷新,不再等整章结束后一次性展示。
升级收益:长章节拆分反馈更及时,用户可边拆边看结果合理性,出现异常时易判断问题段落,已拆出内容不会因等待最终返回而“不可见”。
六、拆分完成提示、自动刷新与空白结果兜底完善
1. 拆分完成提示与自动刷新优化:此前部分场景下,后端拆分完成但前端未及时弹出提示、列表未自动刷新,需手动切换页面才能显示结果;本次补全前端收口逻辑,WebSocket收到done事件后立即执行完成态收口,即使done推送丢失,只要HTTP请求正常返回,也会强制触发完成提示;完成时主动刷新台词列表、角色列表和章节详情,增加提示去重逻辑,避免重复弹窗,让“拆分完成”状态明确可感知。
2. 空白台词与空白情绪兜底:针对拆分中高频出现的text_content为空、emotion_name/strength_name为空或不合法问题,后端新增统一清洗与兜底机制——空白台词入库前直接过滤,不写入数据库;空白角色名自动回退为“旁白”;旁白统一兜底为“平静/中等”;普通角色缺失情绪或强度时自动补默认值;入库层再次拦截空白台词,避免脏数据落库,将模型偶发不规范结果在服务层内部消化,不暴露给前端。
3. 拆分请求链路提速:为减少长章节拆分等待时间,优化拆分调用链路,去掉每个chunk正式拆分前重复执行的额外LLM探活请求,保留真正的拆分请求,减少无意义二次往返,不改变拆分结果,仅缩短整体等待时间。
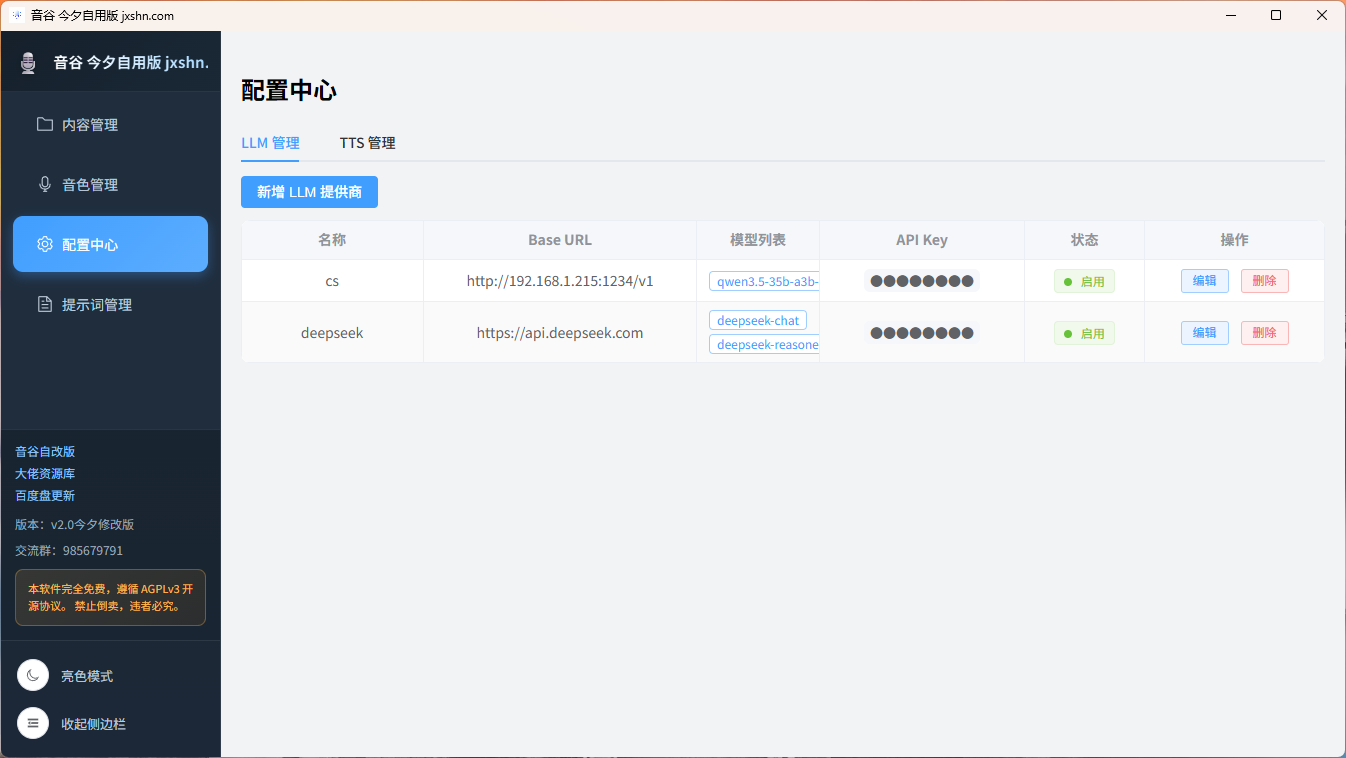
七、LLM本地大模型接入
已支持接入返回JSON格式的LLM本地大模型(这个相当于重大更新,但是只能说DDDD)。
图片预览
下载地址
打开「夸克APP」即可获取。
/~a9723Y7ryu~:/
链接:https://pan.quark.cn/s/17ac56381838




评论抢沙发