简介说明
indextts API 阅读 API 重磅升级!低延迟 + 音色管理 + 缓存全拉满 支持开源阅读小说软件,其他软件应该也通用
本文档说明当前 api.py 这一版接口相对旧版的主要升级内容、迁移方式与使用建议,方便对接阅读 App、局域网调用和本地音色管理。
## 适用范围
- 适用于当前仓库中的 api.py
- 适用于本地启动的 HTTP 服务
- 适用于阅读 App 在线朗读规则接入
## 本次升级重点
### 1. 新增阅读直连接口
新增了可直接给阅读 App 使用的接口:
- /v1/legado/tts - /v1/legado/help
其中:
- /v1/legado/tts 用于真正生成音频 - /v1/legado/help 用于展示可直接复制的阅读规则
帮助页已经内置最新示例,不再保留旧参数写法,避免复制到过期规则。
### 2. 新增低延迟模式
当前接口支持按“体感速度”区分的低延迟参数方案,重点是:
- fast - latency=ultra
说明:
- fast 适合大多数场景,兼顾速度和连贯性
- ultra 更追求尽快出声,但长句连续性会弱一点
- 这不是严格意义上的客户端流式播放,而是更激进的分段与低延迟策略
### 3. 新增结果缓存
为了减少重复请求的等待时间,接口增加了两层缓存:
- 音频结果缓存
- 参考音频特征缓存
效果:
- 同一段文本、同一音色、同一组参数重复请求时,可直接命中音频缓存
- 同一参考音色被反复使用时,可减少重复预处理耗时
### 4. 新增音色管理接口
当前版本已支持更完整的音色管理能力:
- /v1/speakers - /v1/speakers/default - /v1/speakers/preview - /v1/upload_audio
对应能力:
- 获取可用音色列表
- 设置默认音色
- 试听指定音色
- 上传参考音频并注册为新音色
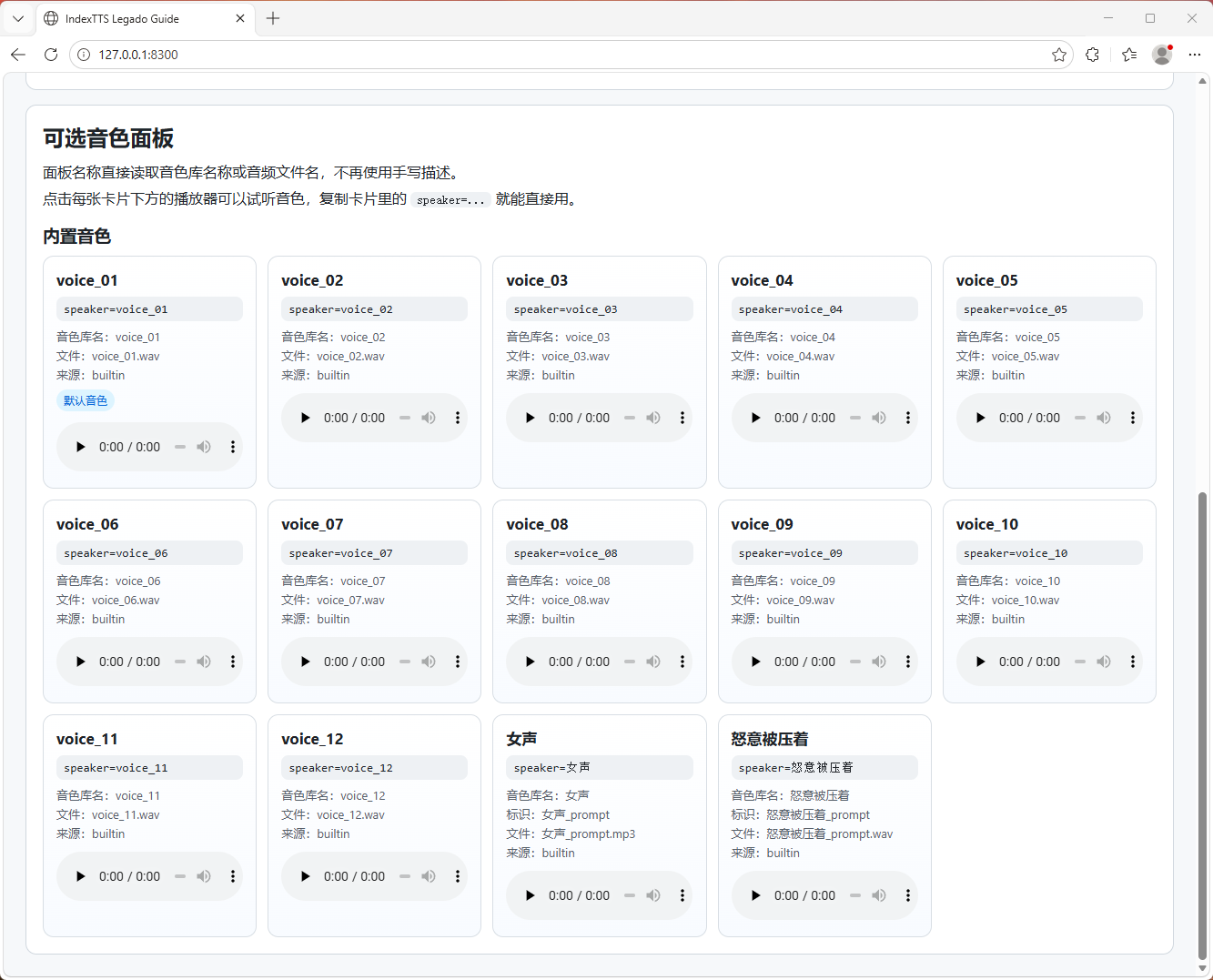
### 5. 帮助页支持音色面板与试听
帮助页中现在会展示音色面板,且资料直接读取现有音色库,不再手写伪描述。
页面特点:
- 按分组展示音色
- 显示音色名、内部标识、来源、参考音频信息
- 每个音色都可直接试听
- 可直接复制 speaker=... 进行调用
### 6. 支持中文音色名调用
当前版本支持直接使用中文音色名称作为 speaker 参数。
例如:
speaker=女声
同时也兼容内部标识调用,例如:
speaker=voice_01
### 7. 增强运行状态与排错能力
新增运行状态接口:
- /v1/runtime
可查看内容包括:
- 当前模型加载状态
- 当前推理设备
- 最近一次 TTS 错误
- 缓存命中情况
- CUDA 可用情况
适合排查以下问题:
- 模型是否成功加载
- 是否走了 GPU
- 为什么 500 报错
- 缓存是否生效
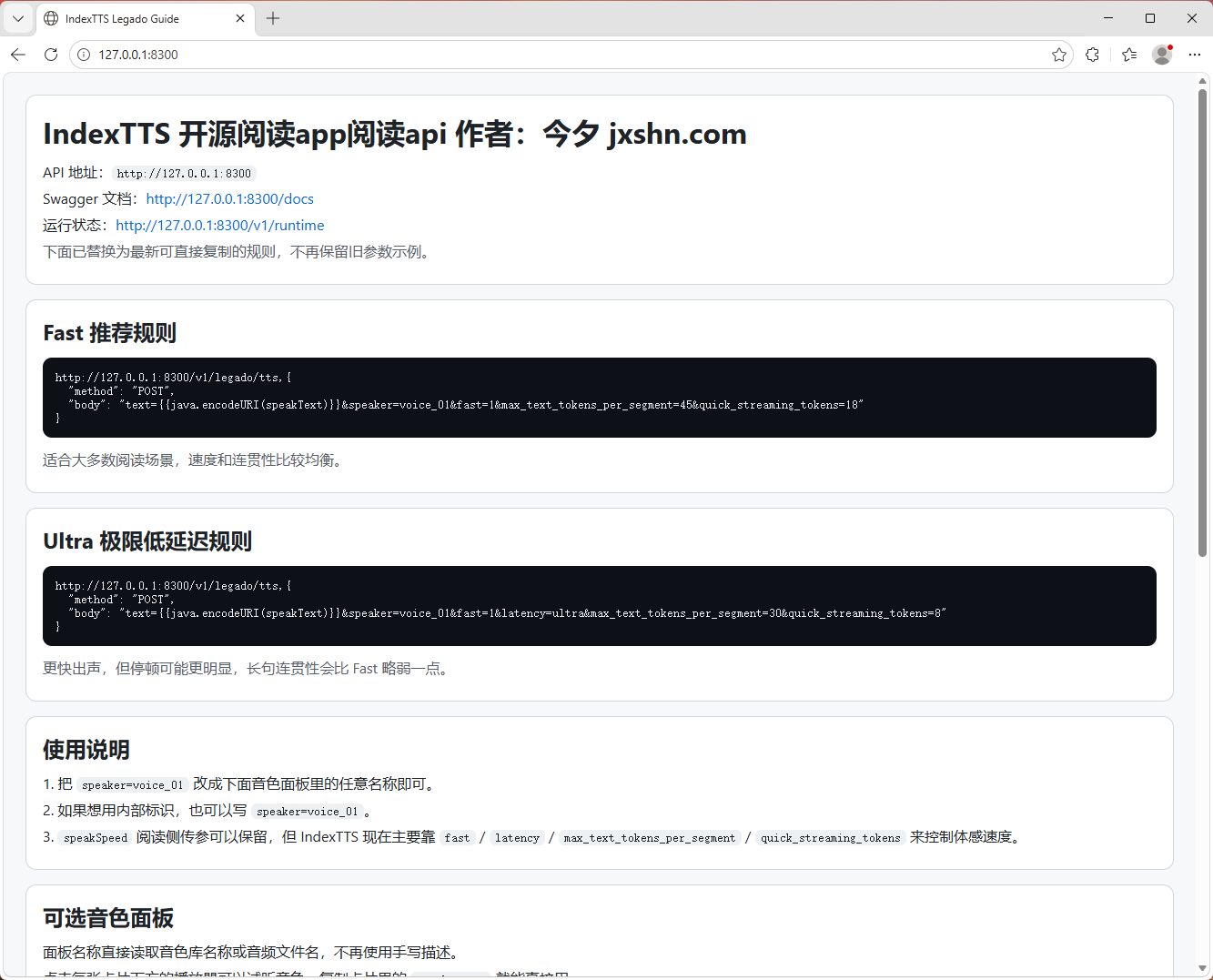
## 当前推荐阅读规则
### Fast 推荐规则
http://127.0.0.1:8300/v1/legado/tts,{
"method": "POST",
"body": "text={{java.encodeURI(speakText)}}&speaker=女声&fast=1&max_text_tokens_per_segment=45&quick_streaming_tokens=18"
}
适合:
- 日常听书
- 兼顾速度与连贯性
- 大部分章节正文
### Ultra 极限低延迟规则
http://127.0.0.1:8300/v1/legado/tts,{
"method": "POST",
"body": "text={{java.encodeURI(speakText)}}&speaker=女声&fast=1&latency=ultra&max_text_tokens_per_segment=30&quick_streaming_tokens=8"
}
适合:
- 更强调尽快出声
- 句子较短
- 对首包等待更敏感的场景
## 与旧版相比的变化
### 1. 旧规则不建议继续使用
如果你之前使用的是更早期的规则写法,建议统一切换到帮助页里的最新规则。
重点原因:
- 旧规则没有体现新的低延迟参数
- 旧规则没有区分 Fast 和 Ultra
- 旧规则不利于后续统一维护
### 2. speakSpeed 不再是主要调速手段
阅读侧虽然仍可传入 speakSpeed,但当前这版接口的主要“速度优化”并不是靠传统变速,而是靠这些参数:
- fast
- latency
- max_text_tokens_per_segment
- quick_streaming_tokens
所以如果觉得慢,优先调这些参数,而不是只调 speakSpeed。
### 3. 音频默认不落盘
当前阅读接口生成的音频主要以 HTTP 响应方式直接返回,默认不作为正式结果写入 outputs 目录。
这样做的好处是:
- 减少磁盘写入
- 降低重复请求的 I/O 开销
- 更适合阅读 App 高频调用
## 推荐迁移方式
### 如果你是从旧版阅读规则迁移
建议直接做这几步:
1. 打开 /v1/legado/help
2. 复制新的 Fast 推荐规则 或 Ultra 极限低延迟规则
3. 把 speaker=女声 替换成你自己的音色名称
4. 在阅读 App 中覆盖旧规则
5. 先用短文本测试,再开始正式听书
### 如果你是从只支持内部音色 ID 的旧版迁移
当前可以优先改成中文名调用,优点是更直观。
例如把:
speaker=voice_01
改成:
speaker=女声
如果你的某个音色名称包含特殊符号,仍建议优先使用内部 ID。
## 常见接口一览
### 阅读相关
- /v1/legado/tts
- /v1/legado/help
### 音色相关
- /v1/speakers
- /v1/speakers/default
- /v1/speakers/preview
- /v1/upload_audio
### 调试相关
- /v1/runtime
- /docs
### 通用合成接口
- /v2/synthesize
## 性能优化建议
如果你觉得阅读时仍然偏慢,可以优先按下面思路调:
### 1. 优先使用 Fast
先从下面这组参数开始:
- fast=1
- max_text_tokens_per_segment=45
- quick_streaming_tokens=18
### 2. 想更快就切 Ultra
可以尝试:
- latency=ultra - max_text_tokens_per_segment=30 - quick_streaming_tokens=8
说明:
- 越激进,越容易提升起声速度
- 但越激进,也越可能损失长句的自然连贯性
### 3. 保持音色尽量固定
同一本书尽量长期使用同一个 speaker,这样更容易命中特征缓存,减少反复预处理。
### 4. 优先使用较短分段
长句或超长段落会明显拖慢首段返回速度。阅读接口已经支持自动分段,但如果正文本身特别长,依然会影响等待时间。
## 升级后建议检查项
升级完成后,建议检查以下内容:
1. api.py 是否能正常启动 2. /docs 是否可访问 3. /v1/runtime 是否显示正常状态 4. /v1/legado/help 是否能看到新规则和音色面板 5. /v1/speakers/preview 是否可以正常试听 6. 阅读 App 是否已经替换成新规则
## 常见问题
### 1. 为什么不是“真正的流式阅读”
当前这版主要是低延迟优化,不是严格意义上的边生成边持续推流播放。
也就是说:
- 已经尽量缩短等待
- 但本质仍是服务端生成后返回音频
### 2. 为什么中文音色名以前不行,现在可以了
旧问题主要集中在请求解析和响应头编码兼容上。当前版本已经对中文音色名调用做了兼容处理。
### 3. 为什么有时第一次慢,后面快
通常是下面几个原因:
- 首次请求会触发模型懒加载
- 首次使用某个音色会做参考音频特征提取
- 后续请求可能命中缓存
### 4. 500 报错去哪里看
优先查看:
- 服务端控制台输出
- /v1/runtime
- /docs
如果是具体参数问题,优先检查:
- speaker 是否存在
- quick_streaming_tokens 是否为整数
- max_text_tokens_per_segment 是否为整数
图片预览
下载地址
https://pan.baidu.com/s/1PChhdaUPQQxXzkFJ0ARPZw?pwd=yn2z 提取码: yn2z
点击链接或复制整段内容,打开「夸克APP」即可获取。
/~8d643XzfyX~:/
链接:https://pan.quark.cn/s/7922cdd3943a




评论抢沙发