项目简介
今夕在线音频转文本工具是一个浏览器端音频转文字、音频转字幕开源项目,对应的代码目录为 https-tools-yiranlaoshi-com-audio-processing。它的核心目标很直接:尽量不依赖复杂后端,让用户在网页里上传音频,就能完成试听、识别、分段预览和字幕导出。
传统音频转字幕工具通常需要服务器接收文件、调用转写服务、再返回结果。这个项目采用了另一条路线:
把主要处理流程放到访客浏览器中完成。音频文件在本地浏览器内解码,转成适合识别的 16kHz 单声道数据,再交给 Web Worker 中运行的 Whisper 模型处理。
对于想做轻量工具站、静态网页工具、前端 AI 演示或私有化小工具的人来说,这种方案很适合参考。
这个项目解决了什么问题
很多人只是想把课程录音、采访音频、口播内容或 MP3 文件快速整理成字幕初稿,但完整搭建一个转写后端往往成本偏高。
这个开源项目把流程压缩到了一个静态网页工具里:
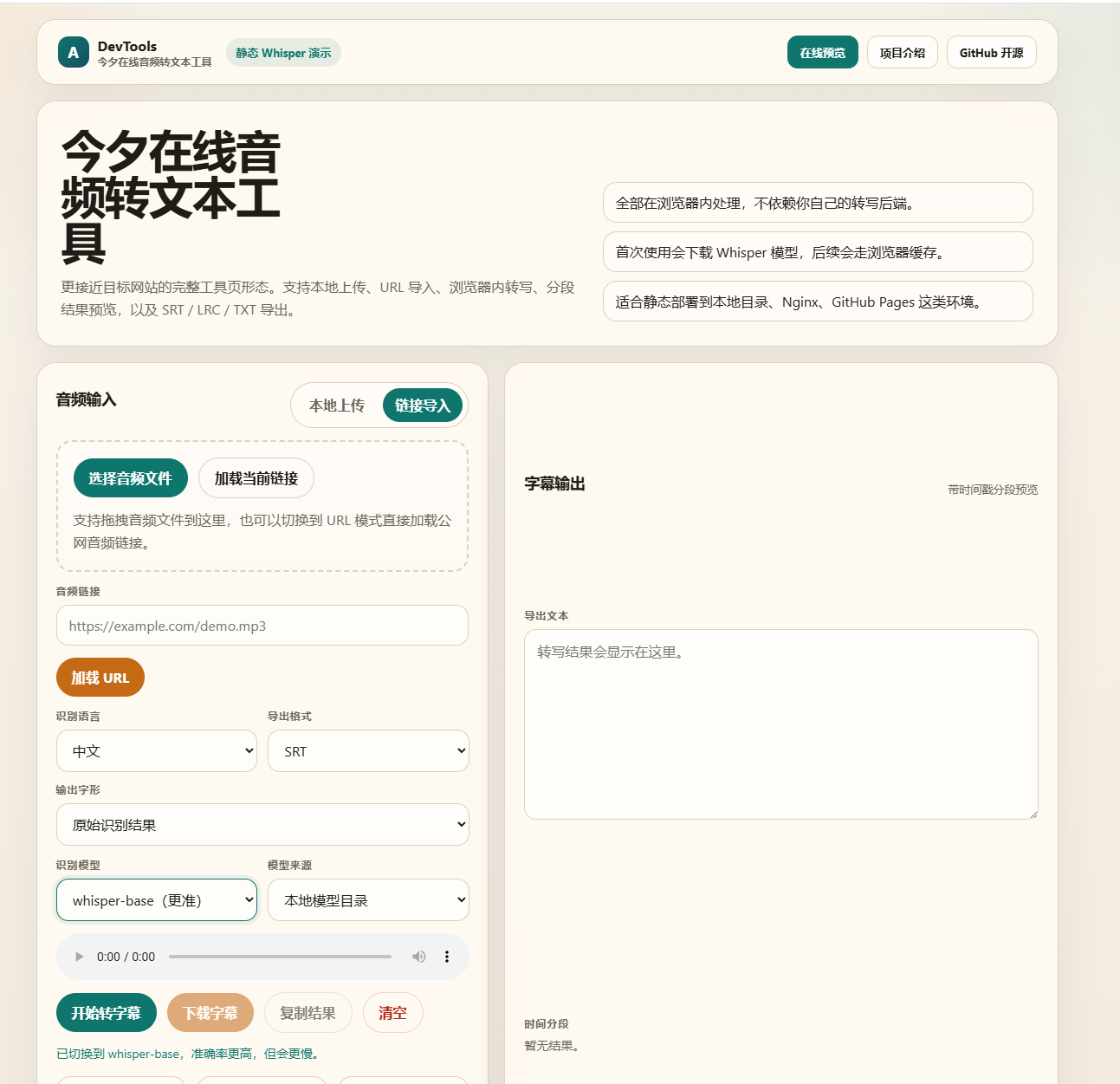
用户选择音频文件后,可以立即在页面中试听
浏览器直接解码音频,不需要先上传到业务服务器
Whisper 模型在浏览器端执行推理
转写完成后生成 TXT、SRT、LRC 三种结果
结果可以复制,也可以作为字幕初稿继续校对
它不是为了替代专业字幕工作流,而是适合解决“先快速拿到一份可编辑字幕初稿”的需求。
核心功能
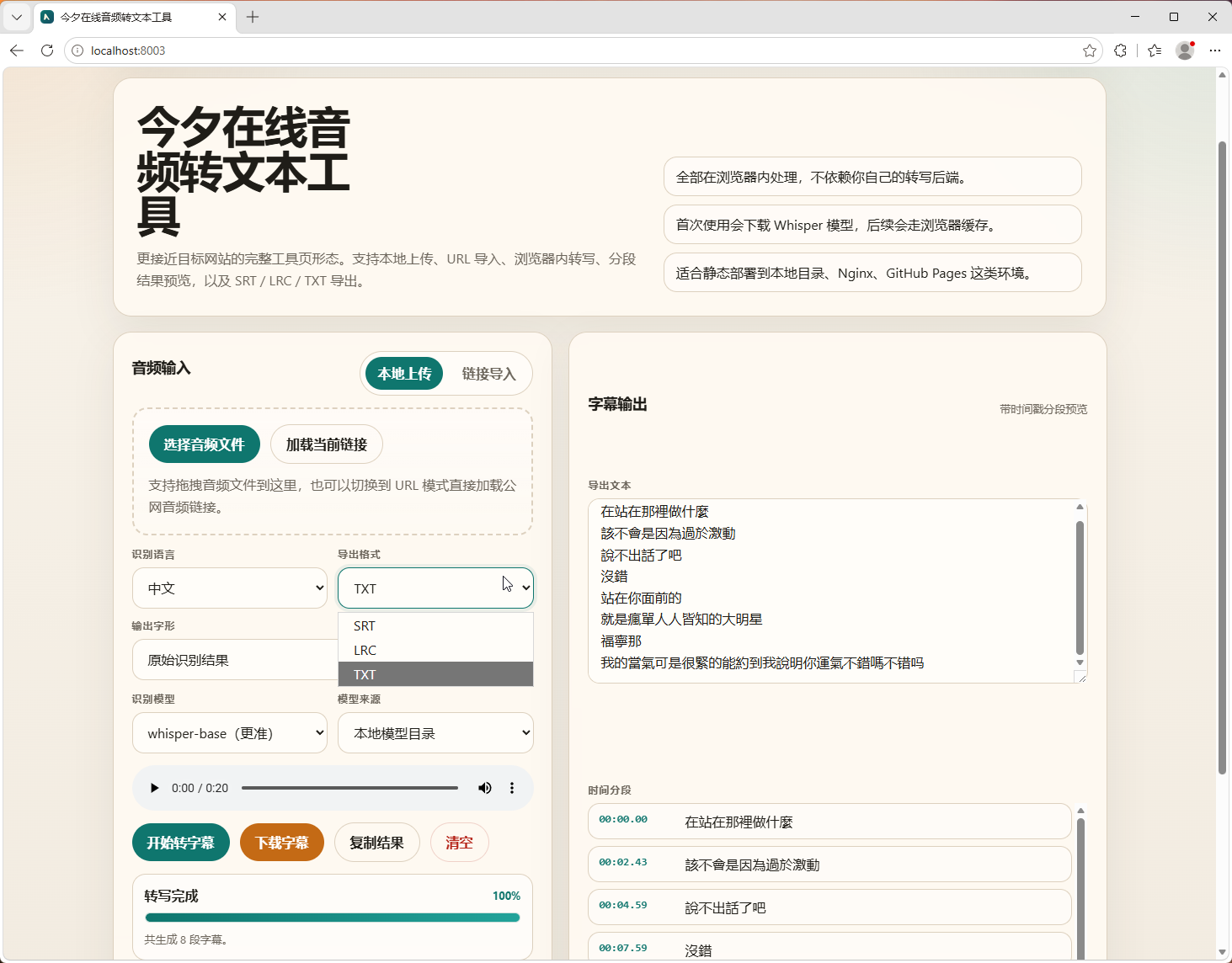
1. 上传后直接试听
项目支持本地音频上传。用户选中文件后,页面会通过浏览器的 URL.createObjectURL 生成本地试听地址,并显示原生音频播放器。
这一步不需要把音频上传到服务器,用户可以先确认文件是否选对、声音是否正常,再开始转字幕。
2. 浏览器内音频处理
上传后的音频会在浏览器中完成解码和预处理。项目使用 Web Audio API 读取音频,并将其重采样为 Whisper 更适合处理的 16kHz 单声道数据。
这个设计让工具更轻量,也降低了服务器侧处理压力。
3. Whisper 模型转写
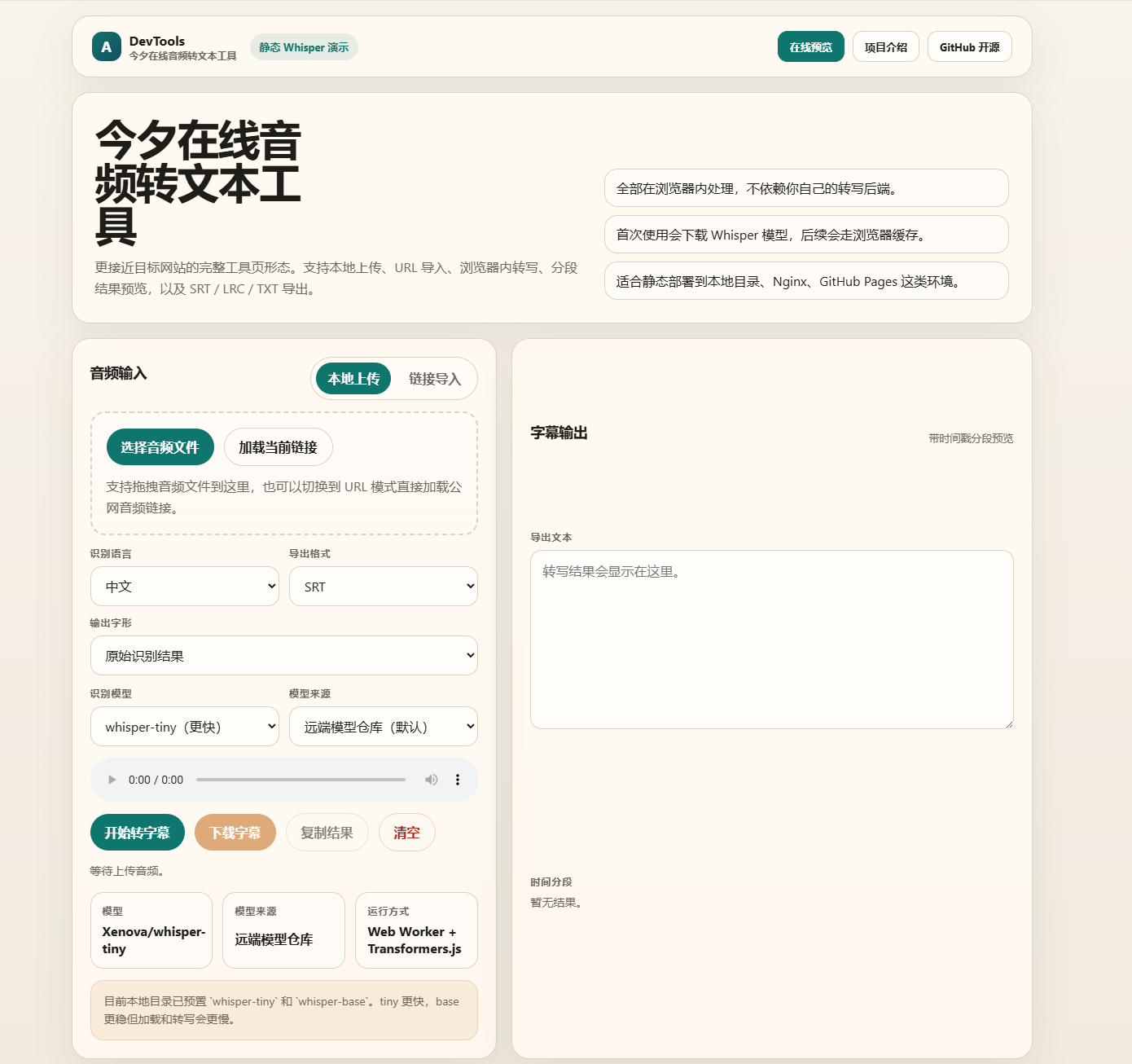
项目使用 Transformers.js 在浏览器中加载 Whisper 模型。当前本地目录已经预置:
Xenova/whisper-tiny
Xenova/whisper-base
tiny 更适合快速测试和低配置设备,base 的识别稳定性通常更好,但加载和转写耗时也会更明显。
4. 支持 SRT、LRC、TXT
转写结果会被整理成多个时间片段,并支持导出为:
TXT:适合纯文字整理
SRT:适合剪辑软件、播放器和字幕编辑工具
LRC:适合歌词或逐句时间轴场景
这让它不只是“语音转文字”,而是更贴近真实字幕整理场景。
5. 静态部署友好
项目包含一个简单的 server.js,可以直接用 Node.js 启动本地静态服务。
同时它也适合部署到 Nginx、Apache、GitHub Pages、Cloudflare Pages 等静态环境。只要服务器能正确返回 .wasm、.js、.json 和模型文件,就可以运行。
技术实现思路
项目的主要结构比较清晰:
index.html 页面结构和工具界面 app.js 上传、试听、音频处理、结果导出 worker.js Web Worker 中加载模型并执行转写 server.js 本地静态服务 vendor/ Transformers.js 和 OpenCC 等依赖 models/ 本地 Whisper 模型文件
页面主线程负责交互和音频预处理,模型推理放在 Web Worker 中执行。这样可以避免模型加载和转写过程长时间阻塞页面。
本地模型路径使用相对当前项目目录的 models/,因此项目部署在域名根目录或子目录时,都能正确读取模型文件。
为什么这个项目值得关注
这个项目的价值不只在“能转字幕”,更在于它展示了一种轻量前端 AI 工具的实现方式。
适合用途
想做一个静态音频转字幕工具
想学习 Transformers.js 如何在浏览器中运行 Whisper
想减少后端转写接口依赖
想做一个可私有部署的字幕初稿工具
想把 MP3、课程录音、采访录音转成 SRT 或 TXT
对开发者来说,它也是一个不错的前端 AI 工具样板:有真实输入、有模型加载、有进度反馈、有导出结果,也有本地模型和远端模型两种思路。
使用建议
第一次使用时建议先选择 whisper-tiny。tiny 文件更小,加载更快,更适合确认浏览器、模型和音频文件是否能正常跑通。
如果 tiny 已经能稳定转写,再切换到 whisper-base。base 更适合中文口播、课程录音、采访整理等对结果稳定性要求更高的场景。
如果部署到线上环境,需要注意:
模型文件体积较大,首次加载会比较慢
.wasm 文件需要正确的 MIME 类型
URL 导入音频时,目标音频地址需要允许跨域
移动端设备性能有限,长音频可能会比较慢
隐私说明
本地上传的音频主要在浏览器中处理,不需要上传到你的业务服务器。这个特性很适合轻量工具和隐私敏感的使用场景。
不过也要注意,浏览器端模型推理依赖用户设备性能。对于很长的音频、很大的模型或低性能设备,等待时间会比较明显。因此更推荐把它作为“生成字幕初稿”的工具,而不是完全自动化的最终字幕生产系统。
总结
今夕在线音频转文本工具是一个实用的浏览器端音频转文字、音频转字幕开源项目。它把上传试听、音频预处理、Whisper 转写、字幕分段和多格式导出整合在一个静态网页工具里。
如果你正在寻找一个轻量、可部署、可学习、可二次开发的音频转字幕项目,这个项目值得参考。它不追求复杂架构,而是把最关键的字幕生成流程尽量放到浏览器中完成,这正是它适合开源和复用的地方。
界面预览
在线预览使用
https://www.jxshn.com/tools/gongju/audio-subtitle/transcribe.php
开源代码下载地址
https://github.com/xielaoban-pro/jinxi-audio-to-text
https://pan.baidu.com/s/1h6E7rHoYIRH3h6COL6zhNw?pwd=eqwp 提取码: eqwp

评论抢沙发